





Nová 4nm generace GPU Nvidia je tady
Už jsou to zhruba dva roky, co Nvidia odhalila své 7nm výpočetní GPU Ampere (akcelerátor A100). Nyní Nvidia představila následníka – novou GPU architekturu Hopper a s ní výpočetní GPU Nvidia H100, založené na čipu GH100. Jde o zatím vůbec nejpokročilejší a nejvýkonnější GPU, poprvé vyráběné na 4nm procesu. Také jde ale o vůbec nejžravější GPU, jaké tu kdy bylo.
Čip GH100
Akcelerátor Nvidia H100 (který vychází z dřívější linie Tesla, ale tuto značku už Nvidia nepoužívá) je opět na servery specializované GPU, u kterého se nepočítá s hraním her. Plně aktivní verze čipu je tvořená 8 bloky GPC, z nichž každá obsahuje 9 podbloků TPC, které se zase skládají ze dvou bloků SM po 128 shaderech či stream procesorech (nebo podle Nvidia „Cuda jádrech“, nicméně nejde o samostatná jádra, spíše jde o jeden „pruh“ SIMD jednotky).
Celkově toto dává 144 bloků SMM a v nich 18 432 shaderů, nejvyšší počet, jaký zatím na GPU založený akcelerátor měl. To je ovšem logické, protože GH100 je první čip z nové 5nm/4nm generace. Každý blok SM obsahuje opět čtyři jednotky Tensor Core pro akceleraci maticových operací, které používají neuronové sítě neboli umělá inteligence. To bude opět asi nejdůležitější nasazení těchto GPU. Plně aktivní čip GH100 by tedy měl 576 tensor jader. Nemá naopak RT jádra pro akceleraci raytracingu.
Obvykle asi H100/Hopper ani vůbec nebude podporovat grafické výpočty, i když se objevila informace (jde o věc nalezenou v datech, které Nvidii nedávno ukradli hackeři), že by podpora pro grafické výpočty mohla být údajně ponechána v jednom bloku GPC, takže by čip měl základní kompatibilitu s 3D grafikou. Uvidíme, zda se toto potvrdí a zda to bude nějak využíváno.
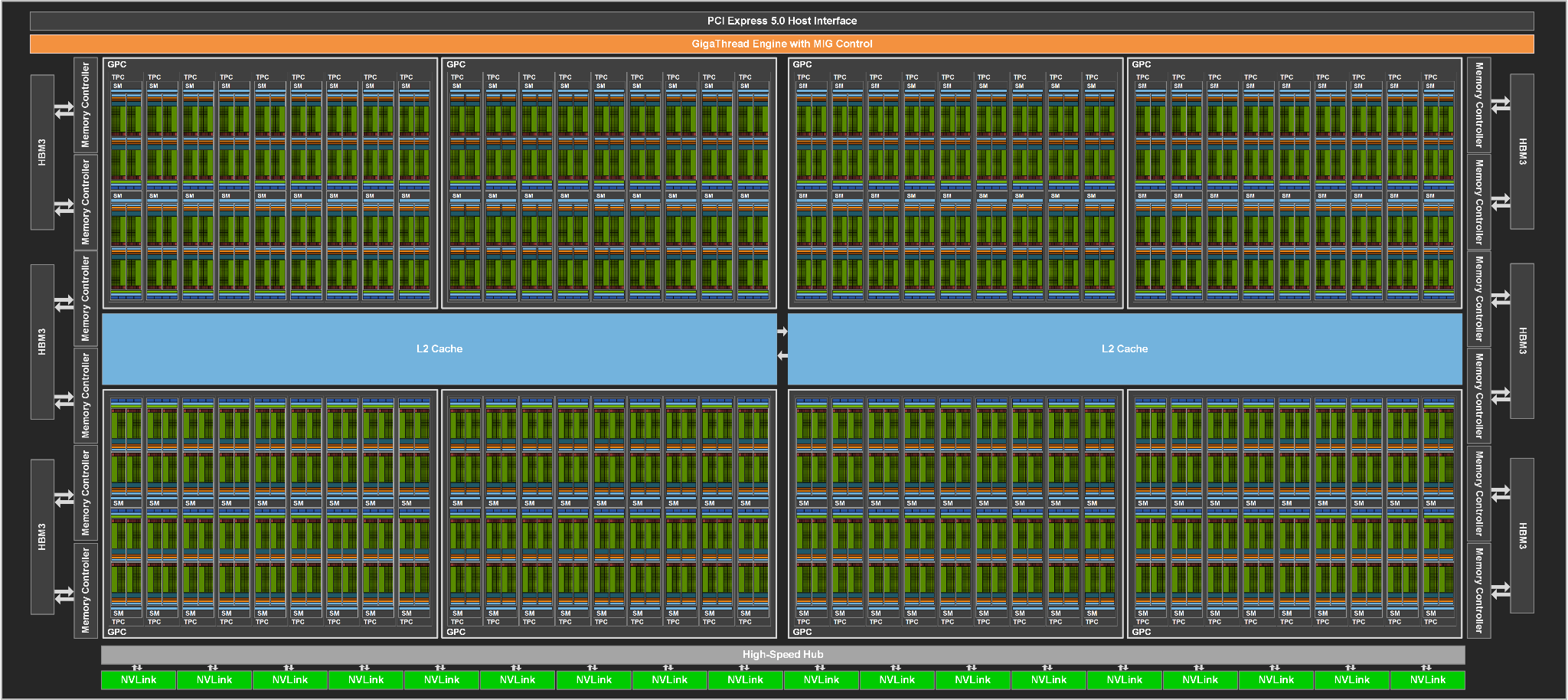
Jako předchozí výpočetní GPU Nvidie bude i Hopper/H100 používat paměti typu HBM, a to s 6144bitovou sběrnicí pro šest pouzder s touto vrstvenou pamětí (toto je tedy nezměněné proti Ampere). Tyto paměti budou moci být buď HBM3, nebo HBM2e, paměťové řadiče zdá se podporují oboje. S paměťovým subsystémem je propojená L2 cache, které má čip celkem 60 MB.

PCIe 5.0 a NVLink 4
Kromě těchto komponent má GPU také novou konektivitu. Jako první podporuje PCI Express 5.0, ale také rozhraní NVLink 4. To má propustnost 25 GB/s stejně jako NVLink 3, ale efektivní frekvence signálu by prý měla být 100 Gb/s místo 50 Gb/s, zatímco počet paralelních linek na jedno rozhraní NVLink klesl ze čtyř na dvě.
GPU GH100 má těchto rozhraní 18, zatímco Ampere jen 12. Propustnost, kterou dokáže NVLink přenést při použití všech, proto stoupla o 50 %, z 600 GB/s u Ampere GA100 na 900 GB/s u GH100.
4nm čip, 80 miliard tranzistorů
Celé GPU je monolitické – je vyrobené jako jediný křemík. Není tedy čipletové, jak se někdy uvádělo v předběžných únicích. Čip má rozměr 814 mm², což je zhruba jako u 12nm čipu Volta/GV100 a méně než u minulé generace Ampere (GA100 měří 826 mm²). Obsahuje 80 miliard tranzistorů.

Nakonec se tedy nepotvrdily informace, že by čip mohl být ještě výrazně větší, než býval dřív tzv. reticle limit. Také je tu ale jiné překvapení – Nvidia toto GPU nevyrábí na 5nm procesu, ale rovnou na jeho vylepšené odvozenině, 4nm procesu. Jde o technologii TSMC, proces by ale snad prý měl být upravený pro Nvidii, která mu říká „4N“ (což kopíruje označení, která používala pro upravený 8nm proces Samsungu, takže je trochu matoucí – TSMC nazývá svůj proces obráceně N4).
Aktualizováno: výrobní proces 4N je podle leakera Kopite7kimi možná odvozený ne od N4, ale od nominálně 5nm procesu N5P. Nvidia tedy svůj upravený derivát trošku přeznačila, ale není to asi moc důležité, protože jak N4, tak N5P jsou rozvinuté varianty stejného 5nm procesu N5, jen přiohnuté pro odlišná určení. Z tohoto důvodu možná původně kolovala informace, že Hopper je 5nm. Ještě data ukradená nedávno hackery zdá se také obsahují informaci o 5nm procesu. Je možná, že přeznačení na „4N“ možná vzniklo až po tomto hacku, dokonce možná i v reakci na něj.
700W verze SXM a verze PCIe
Komerčně prodávané modely budou toto GPU mít částečně ořezané, protože kvůli redundanci je třeba nechat pár jednotek vypnutých. Při velikosti, jakou má čip GH100, bude jen relativně málo vyrobených křemíků bez nějakého výrobního defektu, takže podobně jako u konzolí se od začátku počítá s tím, že část čipu bude vypnutá.
Výkonnější varianta akcelerátoru H100 bude založená na proprietárním mezaninovém formátu SXM5, jehož využití vyžaduje speciální desku a server. Tato verze bude mít aktivních 132 bloků SM (osm GPC a 66 z celkových 72 TPC), což bude dávat 16 896 shaderů a 528 tensor jader Frekvence by měla být někde okolo 1,78 GHz, ale zatím není definitivně stanovena.

GPU Nvidia H100 architektury Hopper v provedení SXM5 (Zdroj: Nvidia)
GPU bude používat 80 GB paměti HBM3, opět tedy bude aktivních jen pět z šesti pouzder, čímž Nvidia může uplatnit i ta vyrobená GPU, kde se u jednoho z pouzder HBM3 po dokončení najde chyba. Paměťová sběrnice proto má šířku jen 5120 bitů, kvůli čemuž je také ořezaná L2 cache na 50MB.
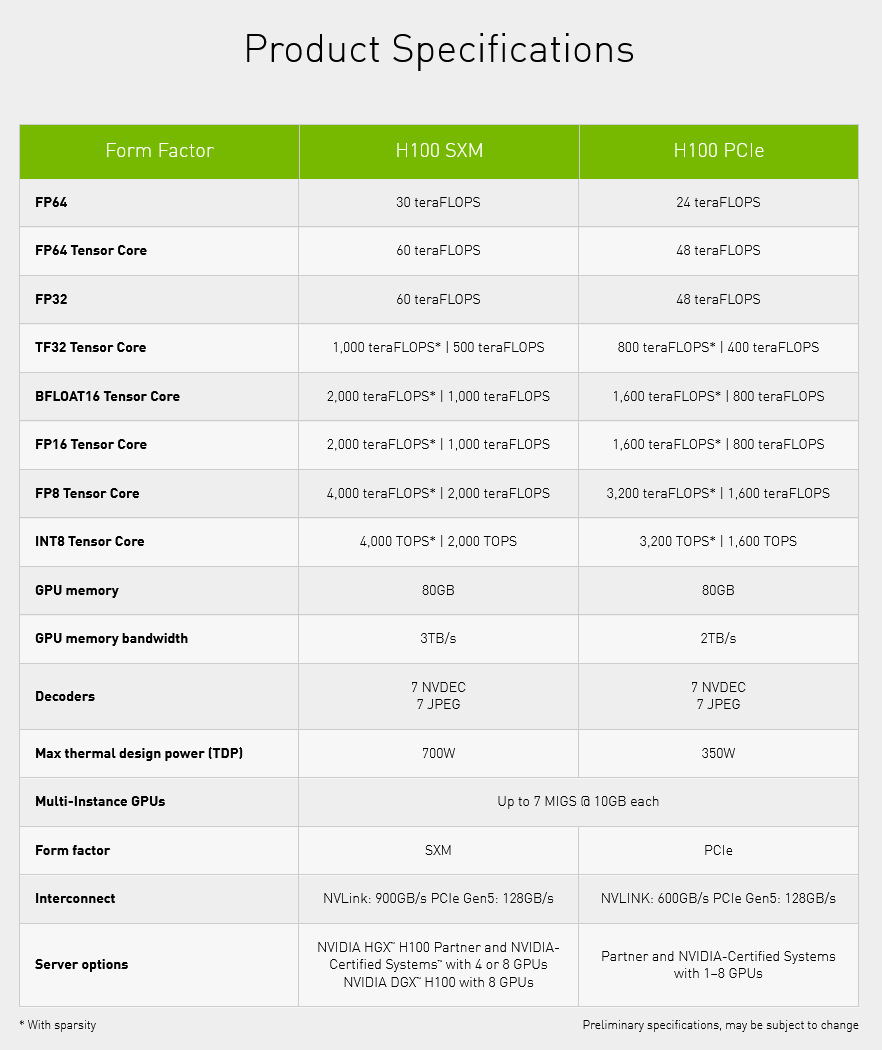
Výkon tohoto GPU má údajně být až 60 TFLOPS ve výpočtech s přesností FP64, ale to je se softwarovými triky (použití Tensor Core), základní FP64 výkon je 30 TFLOPS (a 60 TFLOPS ve výpočtech s jednoduchou přesností FP32). Výkon tensor jader je údajně 500 TFLOPS v maticových výpočtech FP32, 1000 TFLOPS při výpočtech FP16 a podporovaná jsou také čísla ve formátu FP8, kde je výkon až 2000 TFLOPS – stejný výkon je i v možná praktičtějším celočíselném formátu INT8. To je jen čistý fyzický výpočetní výkon maticových operací, při použití funkce Structured Sparsity uvádí Nvidia dvojnásobky. Propustnost pamětí má při použití HBM3 být až 3 TB/s.
Tento akcelerátor bude ale mít také hodně vysokou spotřebu. Ta se v minulé generaci vyšplhala na 400 W a Nvidia H100 v inflaci pokračuje – TDP modelu v provedení SXM5 je 700 W! Chlazení serverů, kde těchto modulů vedle bude třeba osm, nebude žádná legrace.
H100 jako karta PCIe 5.0 bude 350W
Bude existovat také klasické provedení ve formě karty do slotu PCI Express 5.0 ×16. To ale bude mít nižší výkon. GPU bude ořezané jen na 14 592 shaderů (114 SM) a 456 tensor jader. Paměť bude zachovaná v kapacitě 80 GB, ale má být použitá starší (a pomalejší) HBM2e, takže celková propustnost bude jen 2 TB/s. Sběrnice je tedy také zde 5120bitová s 50MB L2 cache. O něco je omezená konektivita NVLink, karta bude mít asi jen 12 rozhraní (takže propustnost jen 600 GB/s). Tato karta bude mít nižší spotřebu, „jen“ 350 W.
Výkon uvádí Nvidia na úrovni 80 % oné 700W verze v provedení SXM5 – 24 TFLOPS ve výpočtech FP64 a 400 TFLOPS v maticových výpočtech FP32 na tensor jádrech a tak dále (800 TFLOPS ve FP16, 1600 TFLOPS v FP8/INT8).
Architektonické novinky: Transformer Engine, Dynamic Programming
Už bylo zmíněno, že Hopper podporuje výpočty v datovém formátu FP8, tedy floating point čísla s jen 8bitovou celkovou přesností, zatímco doteď se 8bitová čísla používala jen ve formátu integer (který má lepší praktickou přesnost, ale malý rozsah). Podpora pro FP8 je součást nové architektury tensor jader, kterou Nvidia označuje jako „Transformer Engine“. Ta podporuje přechod do této zredukované přesnosti zvyšující výkon.
Při trénování AI modelů může být tato zhoršenou přesnost použitá místo FP16 tam, kde je to únosné (software Nvidie by to měl dělat automaticky). Užitečné to má být pro tzv. transformer neuronové sítě. Na GPU Hopper ale podpora FP8 poté může být použitá také přímo pro inferenci.
Architektura Hopper také poprvé přináší podporu pro tzv. dynamické programování. To rozděluje úlohu na menší části, jejichž dílčí výsledky se pak přebírají do řešení celkového problému. Toto rozdělení může umožnit optimálnější výpočet, protože se zpracovaná podúloha může využít opakovaně. Využití dynamického programování má umožnit instrukční rozšíření DPX, které teď má premiéru právě v GPU Hopper.

Dostupnost v druhé polovině roku
Ačkoliv byl Hopper představen už nyní (v úterý), nejedná se zatím o uvedení na trh. Nvidia vždy tato GPU ohlašuje „papírově“ předem. Reálně se ale akcelerátory H100 mají začít prodávat v třetím kvartálu letošního roku. Budou dostupné v serverech různých výrobců, ale také v serverech přímo od Nvidie, která na nich zakládá servery řady HGX.
Zdroje: Nvidia, AnandTech, VideoCardz
Jan Olšan, redaktor Cnews.cz
⠀




