





Nová architektura shaderů, jak je to s 2× FP32 jednotkami
Po stránce hardwaru byl tento měsíc obrazně řečeno celý zelený díky vydání nové generace grafických karet Nvidia, GeForce RTX 3000. Ty jsou založené na nové architektuře Ampere. Co přináší a v čem je nová proti Turingu, probereme v tomto článku: novou architekturu SM stojící za dvojnásobnými počty shaderů nebo výrobní proces nebo charakteristicky obou čipů, které zatím byly odhaleny.
Nová architektura bloku SM a shaderů
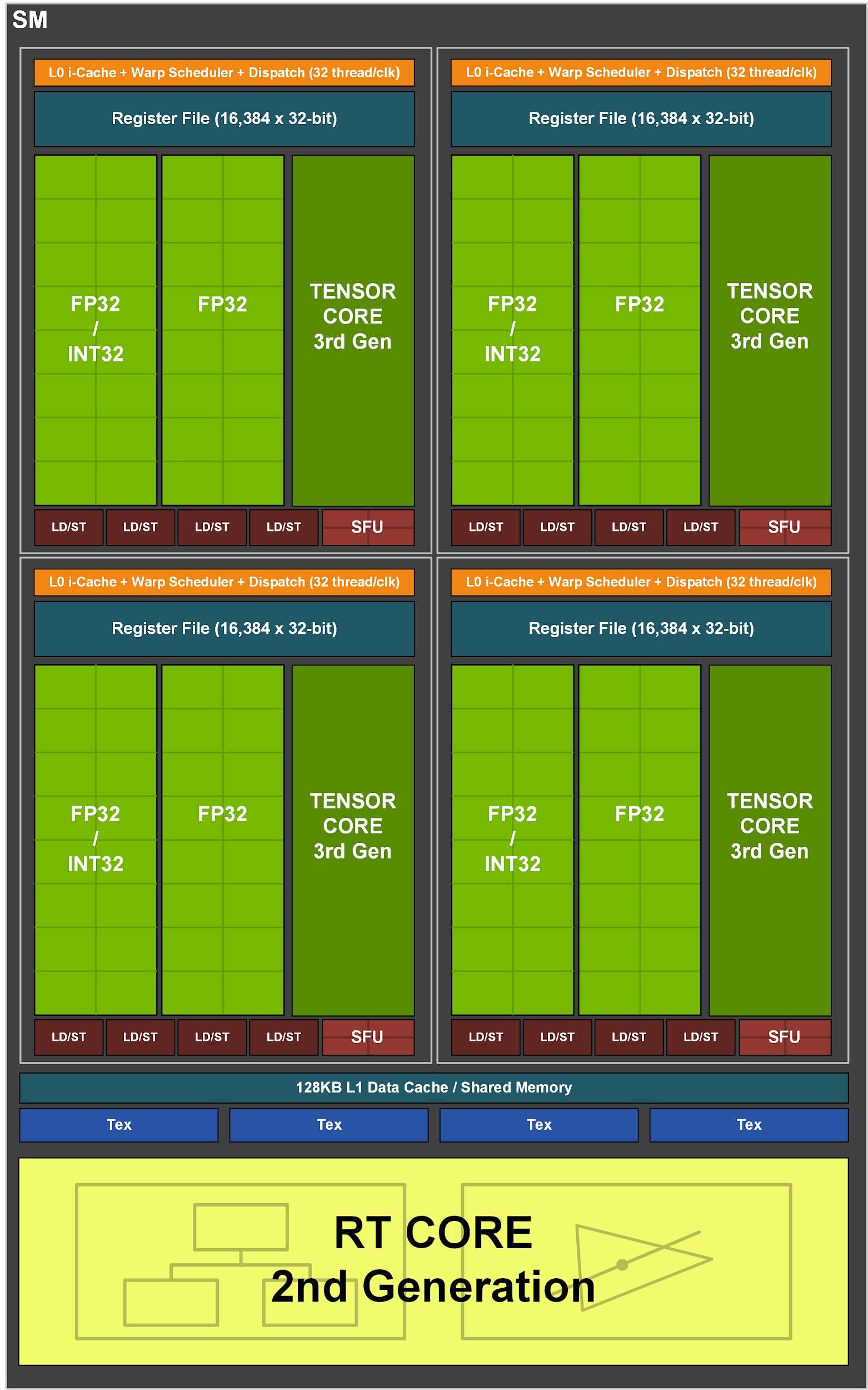
Asi nejdůležitější změna je v shaderech na úrovni bloků SM a souvisí s tím, že Ampere má na jeden blok SM teď 128 místo 64 shaderů („Cuda jader“) a celkové počty jednotek/Cuda jader narostly na víc jak dvojnásobky. Neznamená to tak úplně, že by jeden SM v Ampere měl dvakrát víc prostředků a výkonu, je to trošku složitější.
Ve skutečnosti je tato architektura pokračování změny, kterou Nvidi udělala už v GPU Turing a Volta. Původně u Maxwellu a Pascalu bylo v jednom bloku SM 64 shaderů, které podporovaly instrukce FP32 (floating point operace, které jsou v GPU nejdůležitější) a INT32 (celočíselné). Reálně je to v SM členěno tak, že blok obsahuje čtyři subsekce s warp schedulerem a load/store částmi a každá posílá operace do 16 jednotek FP32/shaderů jako jeden 16-wide SIMD vektor („warp“). Všech 16 jednotek počítá stejnou operaci (warp), jen se stejnými daty. Jeden SM je tak vlastně trochu jako čtyři 16-wide SIMD jednotky (proto je nepřesné mluvit o 64 „Cuda jádrech“).
Zpracování dvou FP32 operací paralelně
U architektur Volta a Turing udělala Nvidia velkou změnu a místo tohoto paralelně k FP32 jednotkám přidala separátní INT32 jednotky schopné pouze celočíselných operací. Subsekce/warp scheduler v Turingu může místo jedné 16-wide operace (warpu) v jednom cyklu poslat ke zpracování dvě – jednu FP32 do hlavních jednotek, a pokud má současně ještě „na holení“ celočíselnou instrukci, tu pošle do separátní INT32 jednotky. Celkově tedy blok SM mohl za jeden cyklus zpracovat 64 FP32 operací jako Pascal, ale k tomu navíc paralelně s nimi 64 INT32 operací. Celočíselné instrukce jsou méně časté (poměr kolísá, průměrně dejme tomu 3:1), ale jejich odesláním do paralelní jednotky se FP32 jednotka uvolní pro další operace a značně stoupne výkon na 1 MHz.

Zdvojení shaderů v Ampere je ve skutečnosti jenom další úprava tohoto uspořádání, která už není tak velká. Nvidia ponechala schopnost bloku SM (respektive subsekce) za jeden cyklus zpracovat dvě operace. Ale tentokrát jsou takto paralelně zapojené ne jednotka FP32 a jednotka INT32, ale jednotka FP32 a jednotka, která dokáže udělat buď operaci INT32, nebo FP32. Ampere tak dovede za cyklus provádět dvě floating point operace místo jedné (což je 2× zrychlení), nebo jednu FP32 a INT32 jako Turing/Volta. FP32+FP32 se ale využije častěji a tak budou většinu času použité obě tyto pipeline (či datové cesty), zatímco u Turingu se INT32 pipeline používala dejme tomu jen z poloviny či třetiny.
U Ampere díky tomuto značně vzroste výkon na 1 MHz, ale ne úplně na dvojnásobek výkonu Turingu. Jednak budou výpočty brzdit i jiné věci, zejména se ale urychluje jen výpočet operací FP32+FP32, kdežto v případě, kdy se sejde operace FP32 a INT32, bude výkon stejný jako u Turingu.
Počet shaderů ve specifikacích
Fyzicky je tak jeden blok SM pořád vlastně tvořený čtyřmi subsekcemi s warp schedulerem posílajícím warpy to 16-wide jednotek, ale tyto 16-wide vektory/warpy může poslat dva. U Turingu ještě Nvidia nepočítala jednotky pro INT32 operace jako separátní shadery, proto tato GPU nemělo zdvojnásobený počet shaderů ve specifikacích. Ale protože v Ampere tato druhá paralelně použitelná jednotka umí dělat i instrukce FP32, už je důvod ji počítat jako samostatný shader, proto má tedy teď jeden blok SM oficiálně 128 shaderů a GPU se stejným počtem SM má teĎ dvojnásobně shaderů.
Například TU104 a GA104 mají zřejmě obě 48 SM, ale u Turinga se to počítá jako 3072, u Ampere jako 6144 shaderů. Výkon v přepočtu na jeden shader kvůli tomuto asi u grafik Turing bude vycházet vyšší než u Ampere, ale to je celkem podružné. Podstatný je celkový výkon GPU nebo výkon na jeden blok SM (ten stoupl).
Mimochodem: toto se týká jen herní verze architektury Ampere. Je zajímavé, že výpočetní Ampere A100 pro servery toto nemá a jeho shadery jsou uspořádány jako v architektuře Volta a celkový počet shaderů se proto uvádí jen 64 na blok SM.
Nové Tensor jádro 3. generace
V bloku SM není jen tato změna. Nvidia aktualizovala také architekturu Tensor jader pro výpočty umělé inteligence na bázi neuronových sítí (používají se pro DLSS) a RT jádra pro ray tracing.
Tensor jádra jsou převzata z výpočetní verze Ampere a jejich hlavní novinka je v použití techniky Structured Sparsity, kdy jádro při maticových operacích neprovádí operace s nulovými hodnotami (algoritmus sám může část hodnot blízkych na nulu zaokrouhlit). Na místo těchto nul se pak posunou ostatní hodnoty.
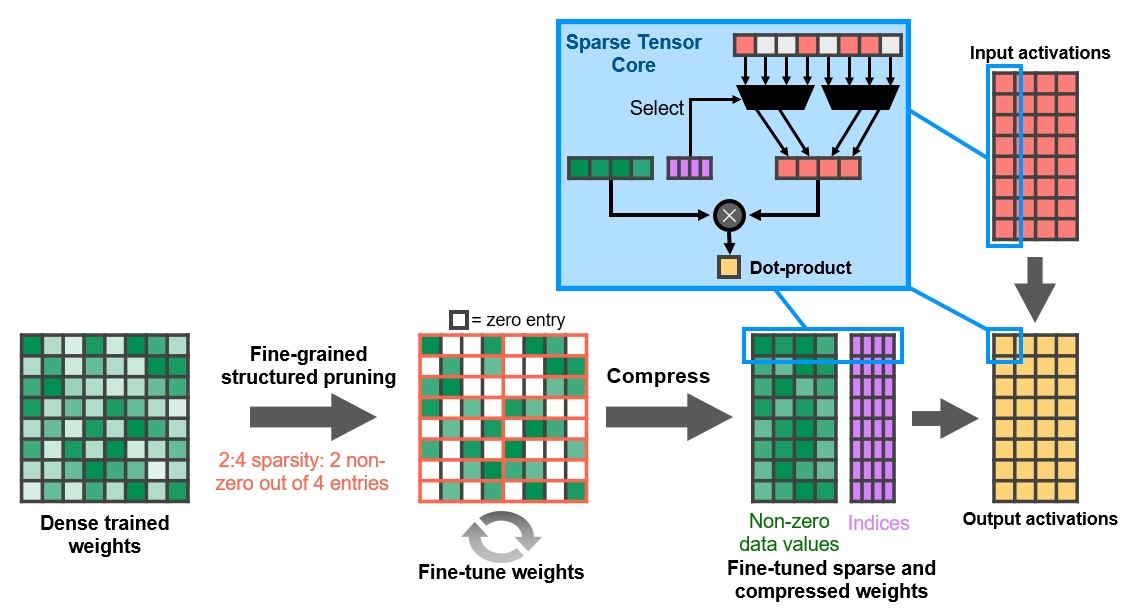
Ve výsledku se celkově výpočet provede jen s cca polovičním počtem celkových násobení, takž efektivně má jednotka ekvivalent dvojnásobku svých skutečných TFLOPS.
V herním Ampere se nachází 4 tensor jádra na jeden blok SM, které každé dá 128 operací FP16 FMA za cyklus. V Turingu bylo osm jader schopných 64 operací za cyklus, takže to by dávalo stejný nezměněný výkon. Jenže s využitím zmíněné funkce Structured Sparsity to u Ampere ve výsledku platí jako dvojnásobek. Nvidia na základě toho uvádí, že výkon v umělé inteligence je dvojnásobný (případně ještě vyšší, protože Ampere má více bloků SM).

RT jádro 2. generace
Jádra pro ray tracing jsou v Ampere teprv druhé generace. Jejich architektura a fungování je asi podobná – stále provádějí hledání průsečíků paprsků s bounding volume boxy v BVH hierarchii a poté s trojúhelníky objektů scény, jak to definuje standard DXR v rámci DirectX Ultimate.

Ovšem podle Nvidie je výpočetní výkon těchto jader, který mají dostupný k provádění těchto operací, výrazně vyšší, až dvojnásobně. RT jádra také mohou nyní pracovat současně s tensor jádry, což u Turingu nebylo dovoleno, tam smělo být aktivní vždy jen jedno z toho.
RT jádra umí hardwarově akcelerovat efekt motion blur
Kromě tohoto zlepšení výkonu má RT jádro v Ampere ještě jednu další novinku. Nvidia zabudovala do jeho architektury schopnost aplikovat efekt motion blur. Spočívá to v tom, že při výpočtu průsečíku paprsku a objektu dochází k temporálnímu zprůměrování s průsečíky pro předchozí časové okamžiky, takže pak je výsledný obraz rozmazaný, jako by byl zvlášť aplikován efekt motion blur.
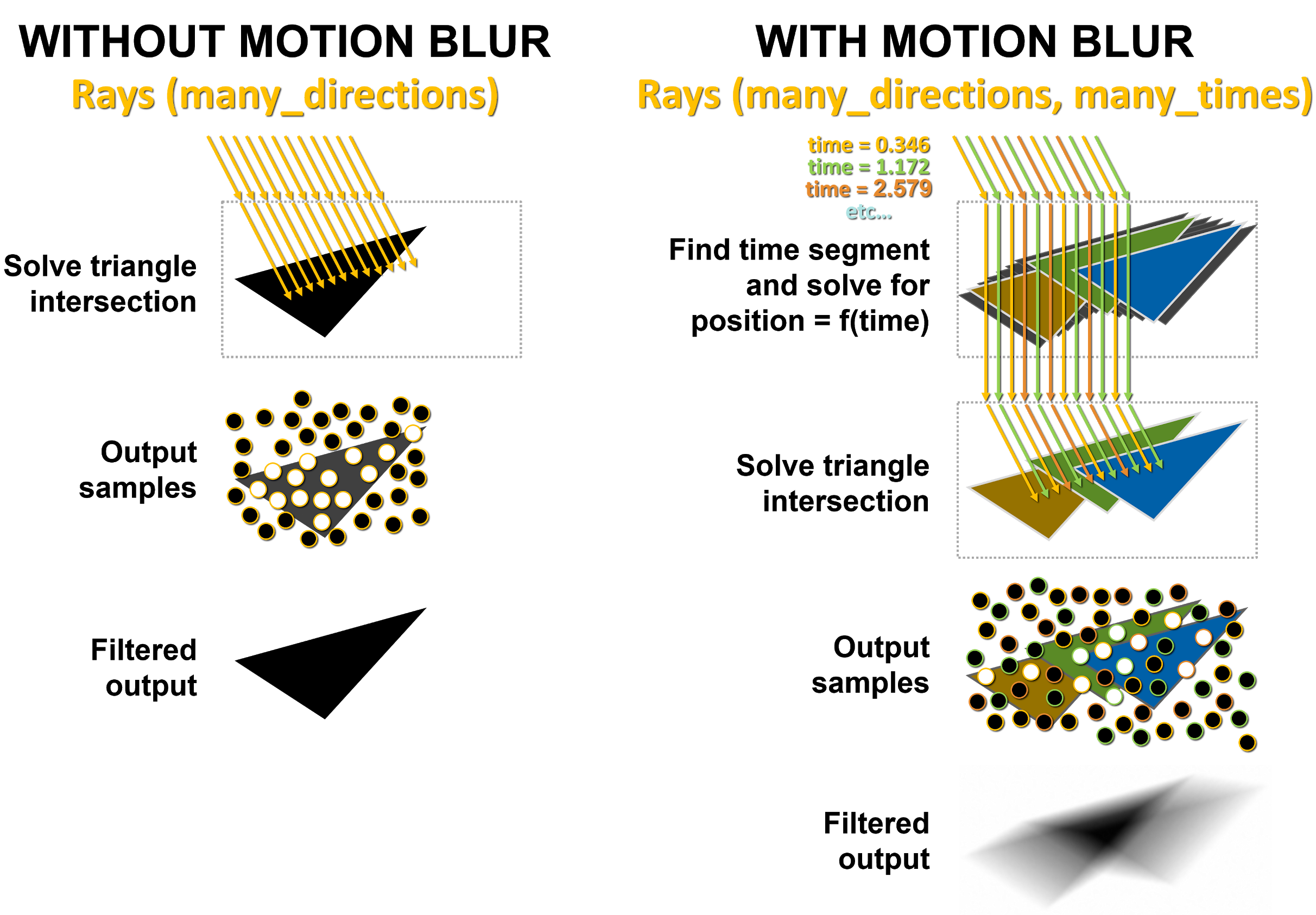
Tento hardwarově prováděný motion blur logicky bude proveden jenom v raytracingové scéně nebo efektu, ne když se hra vykresluje klasickou rasterizací.
⠀
- Contents
- Nový výrobní proces 8N: technologie Samsungu vylepšená speciálně pro Nvidii
- Parametry čipů GA102 a GA104, prvních dvou Amperů
- Nová architektura shaderů, jak je to s 2× FP32 jednotkami
- PCI Express 4.0, HDMI 2.1, AV1, 8K video a 8K (upscalované) hraní





