





ARM poslední dobou uváděl každý rok novou generaci procesorových jader. A nejinak tomu bude letos, jen tentokrát tuto akci přesunul na veletrh Computex. ARM tam tento rok odhalil kompletní linii nových architektur: nové velké „prime“ jádro Cortex-X4 pro maximální jednovláknový výkon, nové prostřední jádro Cortex-A720, jehož rolí je generovat mnohovláknový výkon (jako E-Core Intelu) a konečně i nové malé úsporné jádro Cortex-A520.
Nejvýkonnějším jádrem v generaci bude zase Cortex-X4, navazující na předchozí Cortex-X3. Toto jádro bude mít v mobilech za cíl poskytnout jednovláknový výkon a často proto v SoC bude jen jednou (v čipech pro notebooky to může být jiné). Je to proto, že toto jádro není vyladěné na maximalizaci poměru výkon/plocha a poměru výkon/spotřeba.
Cortexy linie X jsou navržené tak, aby měly co nejvyšší jednovláknový výkon i za cenu toho, že se energetická efektivita a efektivita co do zabrané plochy na čipu zhorší. Zatímco tento přístup pomáhá jednovláknovým aplikacím, mnohovláknové aplikace by v určitém limitu spotřeby se samými jádry Cortex-X dopadly hůře, než pokud by se použilo několik (nejspíše víc) prostředních jader Cortex-A se stejnou spotřebou. Tato jádra jsou tedy specializována na odlišné scénáře a v hybridní architektuře se doplňují. Nebo taková je alespoň teorie.

Cortex-X4 je dosud nejvýkonnějším jádrem, které ARM navrch. Tak je tomu u těchto jader samozřejmě každoročně tím, jak výkon mezigeneračně pořád stoupá. Ale v tomto případě nejde jen o praktický výkon. Jádro je skutečně radikálně silnější (širší) co do architektonické koncepce, v které jde výrazně dál než cokoliv před ním.
Víc ALU než Apple
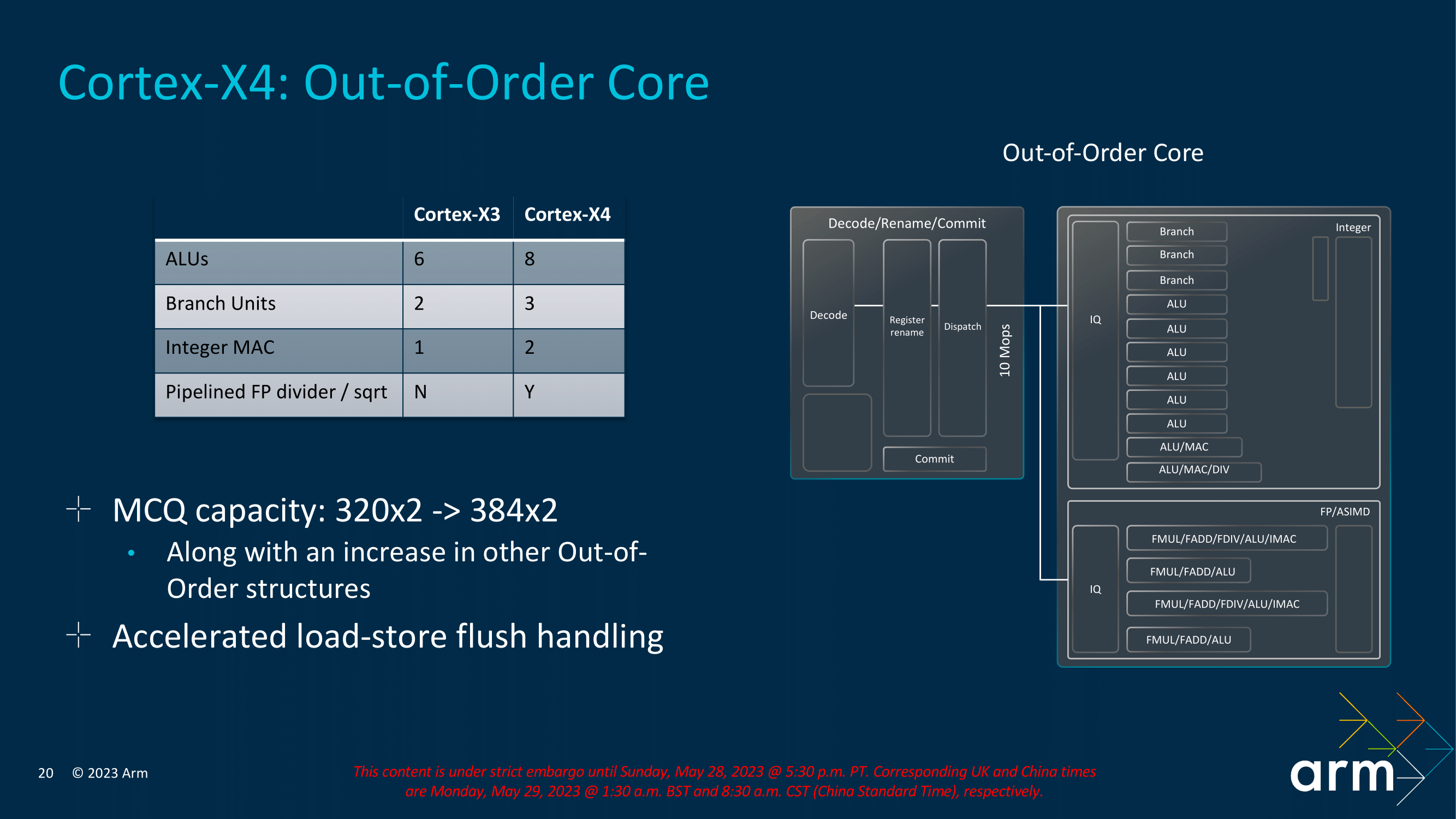
Toto jádro má rovnou osm jednotek ALU pro celočíselné operace (proti šesti v Cortexu-X3 nebo v jádrech Applu a stále jen čtyřem v AMD Zenu 4). Šest ALU je pro běžné jednoduché instrukce s latencí jeden cyklus, dvě další jsou schopné provádět složitější vícecyklové instrukce a mají funkcionalitu celočíselné MAC (u Cortexu-X3 ji měla jen jedna jednotka ALU). Celočíselná dělička je stále jen v jedné z komplexních ALU. Současně byl navýšen i počet jednotek pro větvení, které jsou separátní – ze dvou na tři (zde je to také víc než u Apple a Zenu 4, kde jsou jen dvě).

Také load-store část je rozšířená ze tří jednotek AGU na čtyři. Je možné zpracovat dvě čtení a dva zápisy do paměti za cyklus, nebo tři čtení a jeden zápis (jedna jednotka je univerzální load/store, dvě umí jen load operace a jedna, která je nová, pouze store).

Naopak v FPU zřejmě jednotky nepřibyly, stále má jen čtyři pipeline, a zřejmě také SIMD pipeline pořád mají jen 128bitovou šířku vektorů (oproti 256 až 512 bitovým šířkám jednotek u x86 procesorů). Výkon instrukcí Neon a SVE/SVE2 tedy asi moc nenaroste (pokud mu nepomohou zlepšení v jiných částech jádra). Větší změna proti Cortexu-X3 je zdá se jen v tom, že floating-point dělička bude nově pipelinovaná (dříve nebyla), což výkon těchto instrukcí o dost zvýší. Jejich použití ale není zas tak časté, protože z důvodu vysoké ceny těchto instrukcí se jim programátoři při optimalizaci obvykle snaží vyhýbat.
Jádro už má osm dekodérů, zcela upouští od uOP cache
Na rozšíření jádra ale ARM sází i v dalších fázích, zejména ve frontendu. Procesor má rovnou osm paralelních instrukčních dekodérů, což je také rekord (Apple má také osm dekodérů). Tyto dekodéry dokáží dodávat dalším fázím zpracování osm instrukcí za cyklus. Dispatch pak podporuje až 10 micro-opů za cyklus (ne všechny instrukce se dekódují na jeden micro-op).
Zdá se, že ARM také zkrátil pipeline procesoru, což jde trochu proti evolučnímu trendu ostatních architektur, kde bývají přidávány další stupně (což přesněji znamená, že se fáze zpracování, které v kratší pipeline udělají v jednom cyklu, rozloží do více cyklů). Cortex-X3 měl 11stupňovou pipeline (což bylo množství cyklů, které stálo špatně odhadnuté větvení – byť při získání mikroopů z uOP cache byl postih jen 9 cyklů). Oproti tomu Cortex-X4 má postih vždy jen 10 cyklů a 10stupňovou pipeline.
Více stupňů obvykle jádrům CPU umožní dosáhnout vyšší frekvence, ale roste postih za špatně odhadnutá větvení a s frekvencí také spotřeba. To, že ARM pipeline zkracuje, zřejmě přispívá k vyššímu IPC jádra při nízké spotřebě, bude to ale za cenu nízkého frekvenčního stropu.
Zmíněnou micro-op (uOP) cache, která cachuje micro-opy (už dekódované instrukce), Cortex-X4 zrušil, což je poměrně zásadní změna. Naznačená ale byla už v Cortexu-X3, který ji redukoval. O co jde? Například u procesorů x86 jsou dekodéry kvůli komplikovanosti instrukční sady hodně komplexní a mají i vyšší spotřebu, kvůli proměnlivé délce instrukcí také je těžší jich mít více paralelních. Intel a AMD na to reagovaly tak, že zavedly novou cache (uOP, mikro-op cache), která cachuje již dekódované instrukce. Využívá se toho, že procesor zpracovává stále se opakující smyčky, kdy je možné přeskočit dekódování a vzít dekódovanou instrukci z předchozího průchodu. Uvádí se, že hit rate těchto cache může být třeba až 80 %, takže ony problémy a limity x86 dekodérů reálně z 80 % výpočetního času neexistují.
Apple micro-op cache nikdy neměl, ale ARM ji u jader Cortex-A77 až X3 používal, protože zřejmě stále snižovala spotřebu přesto, že je instrukční sada ARM na dekódování snazší. Prý se to ale změnilo s tím, když byla odstraněna podpora 32bitové instrukční sady a jádro už je čistě ARMv8/ARMv9. To značně zmenšilo plochu dekodérů a jádro Cortex-X3 jich proto použilo víc a micro-op cache se zmenšila. Teď to ARM vzal do důsledku a kompletně vyměnil tutocache za další dekodéry.
Jak už bylo zmíněno, dekodérů je osm a dokáží zpracovat osm instrukcí za cyklus a dodat z nich až 10 operací do dalších fází zpracování (ztv. dispatch). Cortex-X3 měl maximální výstup šest operací za cyklus z dekodérů nebo osm operací z uOP cache. Předchozí fáze fetch, která bere instrukce z L1 instrukční cache a posílá je do fronty dekodérům, je také nově vylepšená a dodává až 10 instrukcí za cyklus.
Pokročilost out-of-order architektury není měřená jen touto „šířkou“ (počtem paralelních jednotek), ale také hloubkou bufferů či front procesoru. V těchto frontách procesor může řadit a přehazovat operace a zlepšovat tak výkon tím, že optimálně vytíží co nejvíce jednotek najednou. To jde tím lépe, s čím větším „oknem“ kódu může procesor pracovat. Toto okno se obvykle pojmenovává ReOrder Buffer (ROB), ARM mu u tohoto jádra říká Micro-op Commit Queue (MCQ). Cortex-X4 hloubku této fronty zvětšil o 20 % – z 320 na 384 instrukcí (respektive v této fázi micro-opů). Pokud jsou dva micro-opy spojené v předchozí fázi zpracování (fused), zabírají jen jednu položku, proto ARM uvádí, že kapacita MCQ je 384×2. Neznamená to ale, že „okno“ má 768 položek. Pro srovnání – v AMD Zen 4 má ROB jen 320 položek (AMD v tomto je hodně minimalistické, Zen 3 měl jen 256), naopak Intel Golden Cove / Raptor Cove už 512 položek a u jader Apple by zřejmě hloubka měla být přes 600 (to jsou neoficiální odhady, protože firma sama nic nezveřejňuje).

Větší L2 cache bez vyšší latence
Procesor má také vylepšené prediktory větvení, u kterých bylo obzvlášť zapracováno na podmíněných větvích. Stejně tak byly vylepšené prefetchery. Obojí je oblast, ve které bývají inkrementální zlepšení u všech nových architektur a toto jádro není výjimka. Cortex-X4 dostal nový temporální prefetcher do L1 cache a L1 cache by měla mít snížený výskyt konfliktů mezi banky. Byl také zvětšen L1 TLB pro data ze 48 na 96 položek.
Další zlepšení je podpora pro 2MB L2 cache, která byla ve fyzickém návrhu přiblížena více k vykonávacím jednotkám a zřejmě díky tomu jí byla zachována stejná latence přes vyšší kapacitu. Díky tomu by snad měla přinášet čisté zlepšení výkonu na 1 MHz bez regresí v některých algoritmech, které jsou na latenci závislé, ale neprofitují z vyšší kapacity. U L2 cache byla také upravena politika plnění a nahrazování dat.
Ačkoliv jádra Cortex-X3 nejsou, jak už bylo řečeno, optimalizována na co nejmenší plochu, toto kritérium je u designů ARMu (oproti třeba jádrům Apple) všude dost akcentované, To je asi dáno preferencemi výrobců mobilních SoC, kteří jsou pod cenovým tlakem a výrobní náklady čipu jsou pro ně na rozdíl od Applu důležité. Cortex-X4 je tedy pořád poměrně malý, podle ARMu bude potřebovat jen o asi 10 % větší plochu než předchozí Cortex-X3 (při použití stejného výrobního procesu a stejné kapacity L2 cache).
IPC a výkon
Výsledkem toho celého má být jádro, které má mít až o zhruba 15 % lepší „IPC“ neboli výkon na 1 MHz frekvence než Cortex-X3. Tento údaj je při stejném taktu CPU, stejné L3 cache a při stejné propustnosti a latenci použitých pamětí. Je třeba říci, že nejde o výsledky naměřené na reálném hardwaru, ale o simulaci.
Reálně bude nárůst v každé aplikaci samozřejmě jiný. Zdá se, že vyšší nárůsty IPC jsou v mnohovláknových aplikacích (Speedometer2: +24 %), ale v jednovláknových aplikacích naopak může zlepšení být nižší. Geekbench 5 a Geekbench 6 mají zřejmě nárůst IPC jen asi +7 % až +8 %. Nejblíže udávanému průměrnému zlepšení je z úloh, které ARM ukazuje ve slajdech, SPEC2017 (SPECRate2017_int_base), kde je zlepšení IPC o +14 %. Benchmarky SPEC vždy s procesory ARM vykazovaly dobré (a možná nadprůměrné proti jiným úlohám) nárůsty, ať už je důvod jakýkoli.

Alternativně jádro má dosahovat stejného výkonu jako Cortex-X3 při až o 40 % nižší spotřebě (díky vyššímu IPC totiž může běžet na nižší frekvenci). V praxi si ale výrobci vyberou místo snížení spotřeby zvýšení výkonu, takže toto se asi nikde moc neprojeví.
Cortex-X4 by podle ARMu měl dosahovat frekvence až 3,4 GHz. Nebude tedy v tomto ohledu škálovat moc vysoko – jak už napovídá malý počet stupňů pipeline – což zase poněkud omezí absolutní výkon. Vysoké IPC je totiž jen jednou částí rovnice. Například jádra Applu už také dosahují vyšších taktů, nemluvě o procesorech Intelu a AMD, které se už pohybují v pásmu 5,5–6,0 GHz, což dává 60–75 % výkonu navíc.
DSU-120
Propojovat tato (a sourozenecká menší) jádra v čipech bude logika DSU-120. Ta bude podporovat celkově až 14 jader a až 32MB L3 cache, kterou budou sdílet. Zřejmě by tedy mohly být dostupné konfigurace jako 4 velká jádra + 8 prostředních jader + 2 malá jádra. Explicitně je podle ARMu podporovaná i kombinace 10 jader Cortex-X4 a čtyř Cortexů-A720, což by mohly používat výkonné notebookové procesory.

Článek pokračuje na další straně.
⠀




