





Cortex-X3: new fastest ARM core with clock speed up to 3.6 GHz and 6 ALU
ARM has been introducing new CPU cores annually for the last few years. This year, the company is unveiling the second generation of CPU cores based on the ARMv9 instruction set. Among them, a new highest-performance Cortex-X3 core with significantly expanded computing resources and 6 ALUs like Apple’s cores. This architecture will boost the single-core performance of Android phones, but it’s supposed to go into laptops as well.
ARM has unveiled the Cortex-X3 in its second-generation ARMv9 core line-up, which will play the role of a “prime” core in phones – that is, a core of which only one is needed in the chip and its job is to provide peak performance for single-threaded applications. In phones, then, the other performance cores will be the smaller “middle” or medium category, which will be covered by the second newly revealed Cortex-A715 core, which is a replacement for the previous A710. ARM hasn’t revealed any new small core yet, so the X3 and A715 will still be paired with last year’s Cortex-A510 architecture.

Cortex-X3: the new most powerful ARM core
While the previous Cortex-X2 core (discussed in detail here) already removed support for 32-bit mode, Cortex-X3 further benefits from this move. The core has reportedly been overhauled in many ways to make it optimal for the 64-bit instruction set (AArch64). This core should reap the rewards of ARM not having to bother with compatibility with older versions of the instruction set.
Therefore, the Cortex-X3 frontend has undergone a lot of changes, which are related to the instruction set change. The frontend is still separated from the rest of the core with the branch predictors running ahead of the main code processing, before the fetch of instructions from the L1 cache. This frontend has the ability to process a high number of instructions per cycle, so that after a frontend restart due to a misprediction, it quickly fills the queue for the next processing stages.

This allows for faster recovery from a branch mispredictions, but this lookahead-running branch predictor also acts as a prefetcher that prefetches data from the L2 cache and L3 cache, so that when the code is actually processed, the core has it ready or the time spent waiting for data is reduced. In Cortex-X3, this capability has been further enhanced, the prefetcher works with a larger “window” of code in advance.

At the same time, the branch predictor has been improved, its accuracy is to be enhanced by larger Branch Target Buffers. The small L0 BTB has been increased to tenfold the capacity, and the second level BTB has been split into two levels – L1 along with the newly added L2 BTB – which together have a 50 % larger capacity. The L0 prediction should have a latency of 0 cycles, and it can then be corrected by more accurate prediction (available with a slightly higher latency) of the other levels. So far ARM has used one such high-precision predictor on top of the L0 one, but in Cortex X3 a slightly faster “intermediate predictor” has been slotted in between them.
The core also has a new predictor dedicated to indirect branches, which are handled with better prediction accuracy and lower latency than in previous cores. The prediction accuracy of conditional branching is also expected to improve.
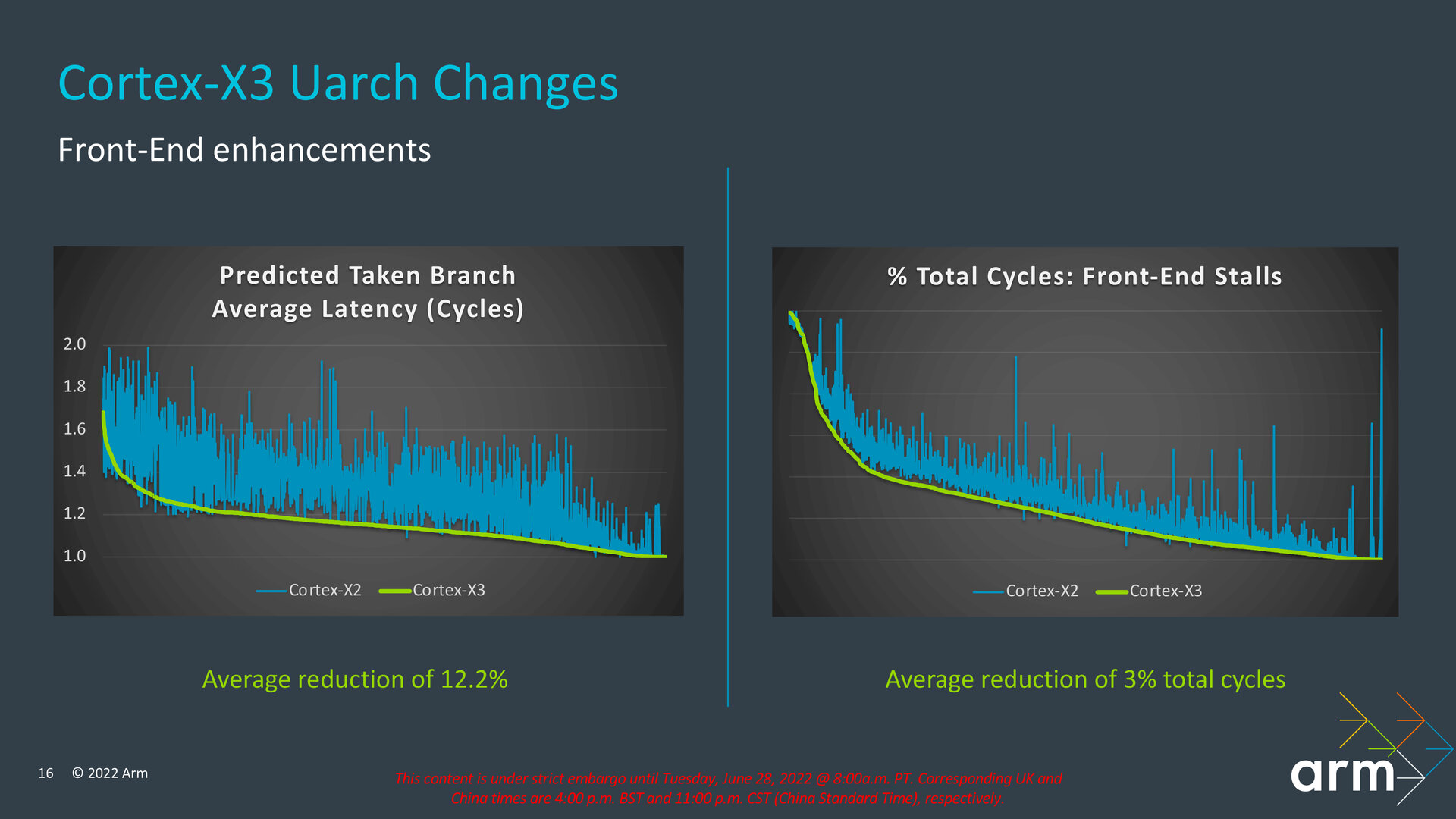
ARM says that overall, Cortex-X3 should reduce the number of mispredicted branches by an average of 6.1 % compared to the X2 core. It also reduced the number of cycles wasted due to Frontend stalls due to mispredicted branches and “bubbles” created during processing by 3 %. The performance improvement in processing the predicted taken branch should result in the number of cycles (latency) that an average taken branch costs being reduced by 12.2 %. This is due to the fact that the more powerful lookahead and prefetching reduces the amount of “bubbles” in the pipeline that are created when jumping in the code due to branching.
Moving away from the uOP cache, the return of decoder maximalism?
A big change has happened in the decoding stage. The Cortex-X3 has increased the capacity of the fetch stage from five to six instructions per cycle, and there are six decoders instead of five, so they can also process six instructions per clock. This is due to the fact that the purely 64-bit decoders take up less space after shedding 32-bit functionality and probably also have lower power draw.
Interestingly, the ARM team has beefed up the decoders at the expense of the microOP cache, which stores already decoded instructions. It has shrunk from 3,000 entries to just 1,500 (which is same as in the Cortex A77, the very first core that introduced the uOP cache). But even this half-size uOP cache can deliver the same eight microOPs per cycle. At the same time, the core has filters that, compared to the previous generation, are a bit stricter in selecting the operations that are stored in the uOP cache, which will improve the utilization of this limited capacity.

This rebalancing is probably due to pure 64-bit decoders becoming cheaper in terms of transistors and power consumption, so the benefit of the processor being able to skip decoding due to the uOP cache has diminished. This is in contrast to x86 processors, for which their complete decoders are more expensive and therefore they have fewer of them and rely more on the uOP cache (AMD Zen 2 and Zen 3, for example, have a uOP cache with a capacity of 4000 operations).
ARM has likely reduced the uOP cache for one additional reason – one phase/stage in the pipeline has been eliminated (the uOP cache now comprises of only one phase instead of two). This has reduced the number of pipeline stages affected by branch misprediction from 10 to 9 (so the misprediction penalty is 9 cycles instead of 10).

Reorder Buffer has outgrown 300 instructions
ARM has also enlarged the “window” in which out-of-order instruction execution, reordering, and optimizing the execution unit utilization takes place. The Reorder Buffer is 320 entries deep (it was 288 entries for the Cortex-X2), which is somewhere between AMD’s Zen 3 and Intel’s Sunny Cove (Ice Lake).
Fused pairs of microOPs should only occupy one position instead two, so that the depth can be effectively greater when they are used. ARM also states that the mechanism handling register renaming has been improved to better handle a larger out-of-order window.
The core now has six ALUs
There are also big changes in the compute units themselves, which are assigned to the operations after this out-of-order phase. Cortex-X3 increased the number of ALUs from four to six. This is equal to Apple’s famous cores with leading IPCs, and for example Golden Cove in Alder Lake processors has only five ALUs, while AMD is still sticking to just four ALUs since the first Zen, though perhaps Zen 5 will change that.
The Cortex-X3 core has four simple ALUs (instead of two) that process single-cycle uOPs. There are still only two complex ALUs that can process two-cycle and multi-cycle instructions. One of these complex ALUs supports integer division. The core also has two separate units for branching.
The integer part of the core can read 32 bytes per cycle instead of 24 bytes. The Cortex-X3 should still have three AGUs (load/store units), with two supporting both reads and writes and the third supporting only reads (so the core can handle two writes per cycle, or three reads, or a combination, but no more than three operations per cycle). Performance should be further augmented by general prefetcher improvements, with the core having new engines that try to capture patterns in data requests.

The FPU and SIMD unit of the core still has four pipelines, there was no expansion here. The core also apparently still operates with 128-bit SIMD vector widths (also for SVE/SVE 2 instructions) like the Cortex-X2. Thus, the theoretical computational throughput of SIMD instructions has not increased, although further improvements in the core should of course also improve the performance that the Cortex-X3 will be able to achieve in the applications in question.
ARM states that the Cortex-X3 should be paired with 1MB of L2 cache (L2 is reserved for one core, but the SoC will have a shared L3 cache) for ideal performance. Optionally, it is possible to reduce the L2 cache to 512KB to reduce the core area, but this will reduce performance and degrade power efficiency. 1MB L2 cache is expected to reduce the data requests from the L3 cache by up to 26.9 %.
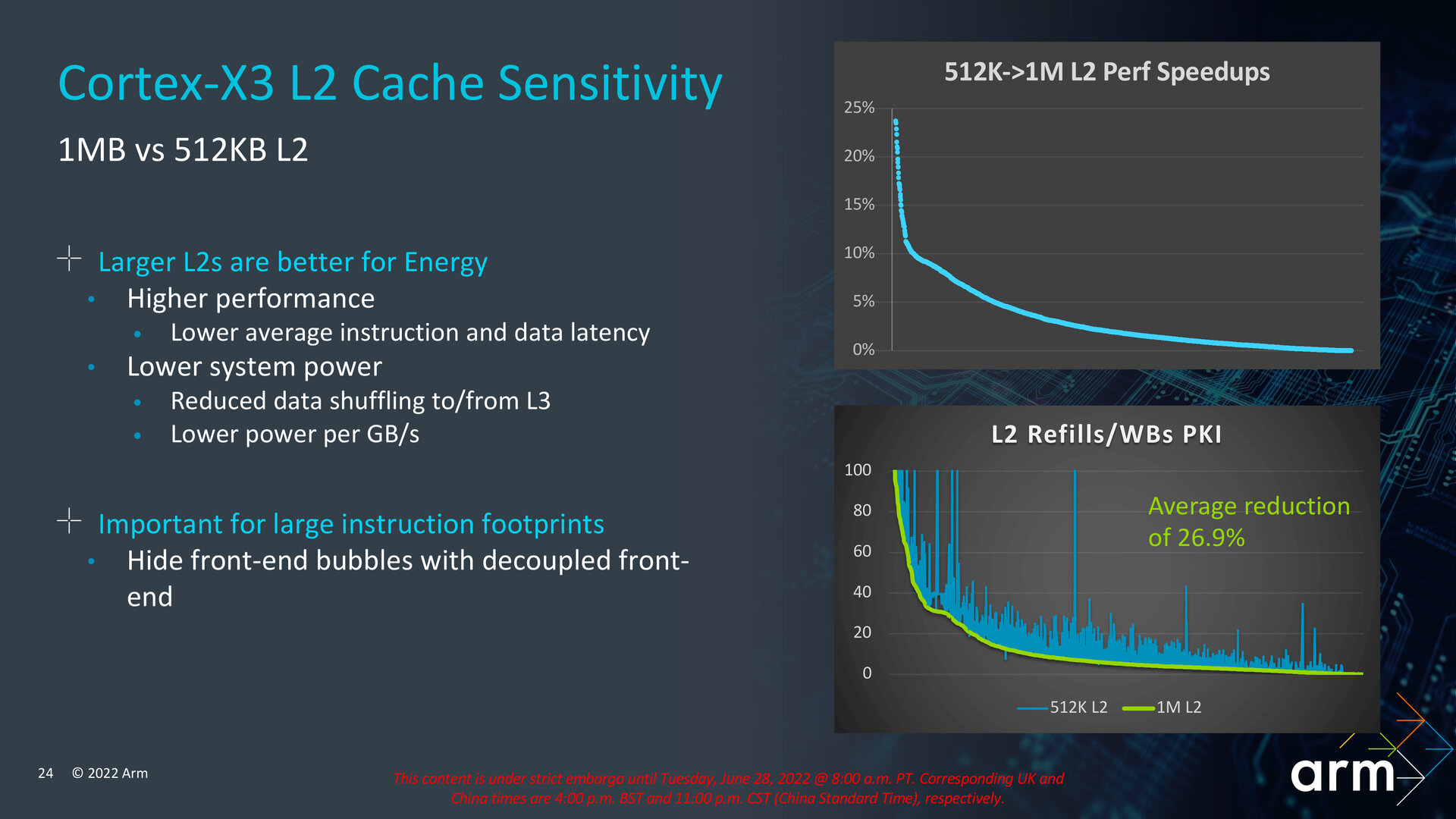
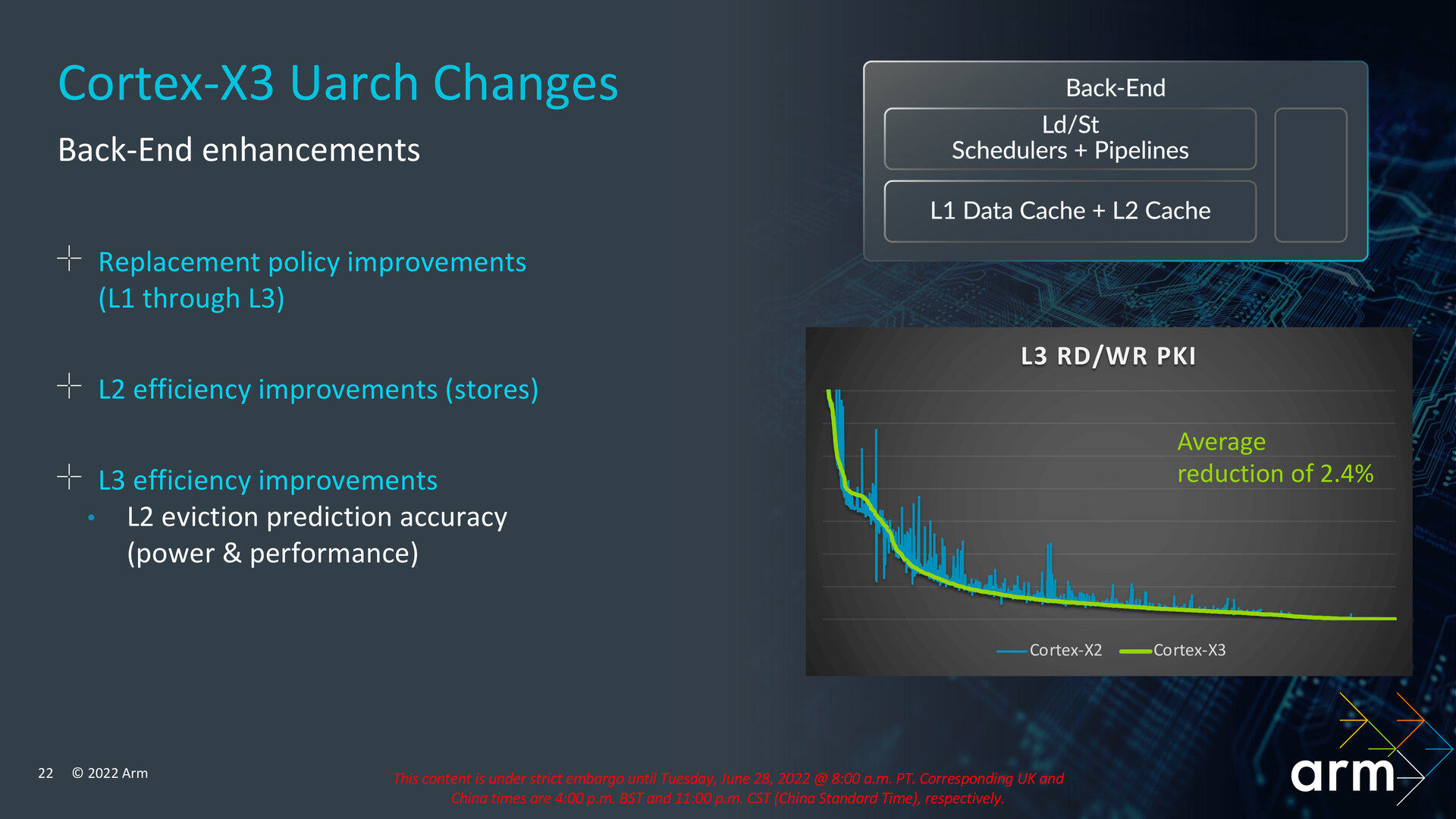
The capacities of the L2 and L1 caches apparently remain unchanged, but there have been efficiency improvements due to changes in cache policy (i.e., controlling which data stays in the cache and which is replaced).
11 % better IPC
According to ARM, Cortex-X3 should have about 11 % higher IPC (performance per 1 MHz) in an implementation with 1MB L3 cache. This is supposed to be a geometric mean from different workloads, it seems to be only +10 % in Geekbench 5, +11 % in SPECint 2006, but probably only +8.5 % in SPECint 2017 according to the charts in the presentation.
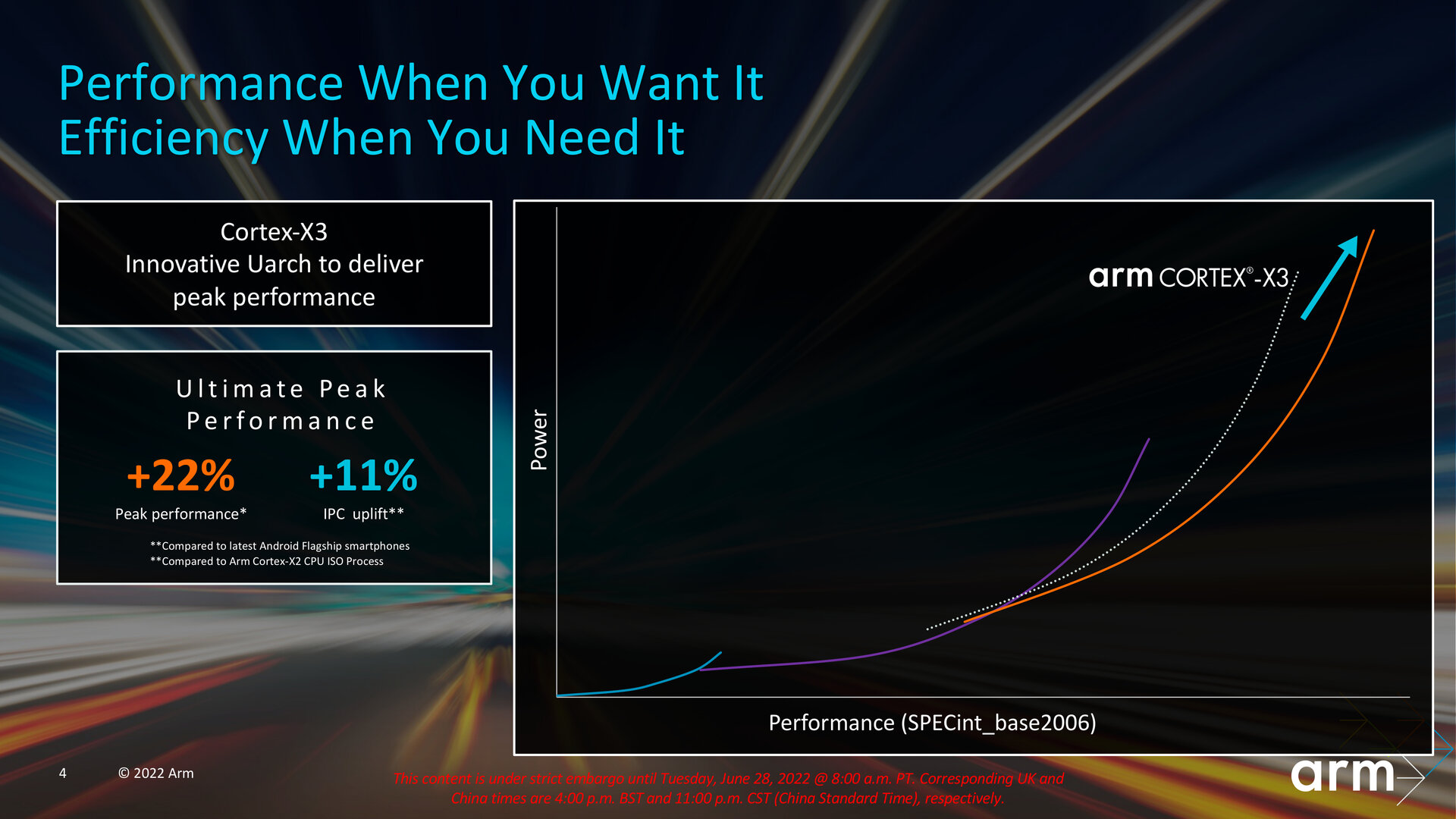
ARM also reports an IPC improvement against the Cortex-X1 generation (i.e. comparison over two years), with the Cortex-X3 having a 22 % better IPC against this core.
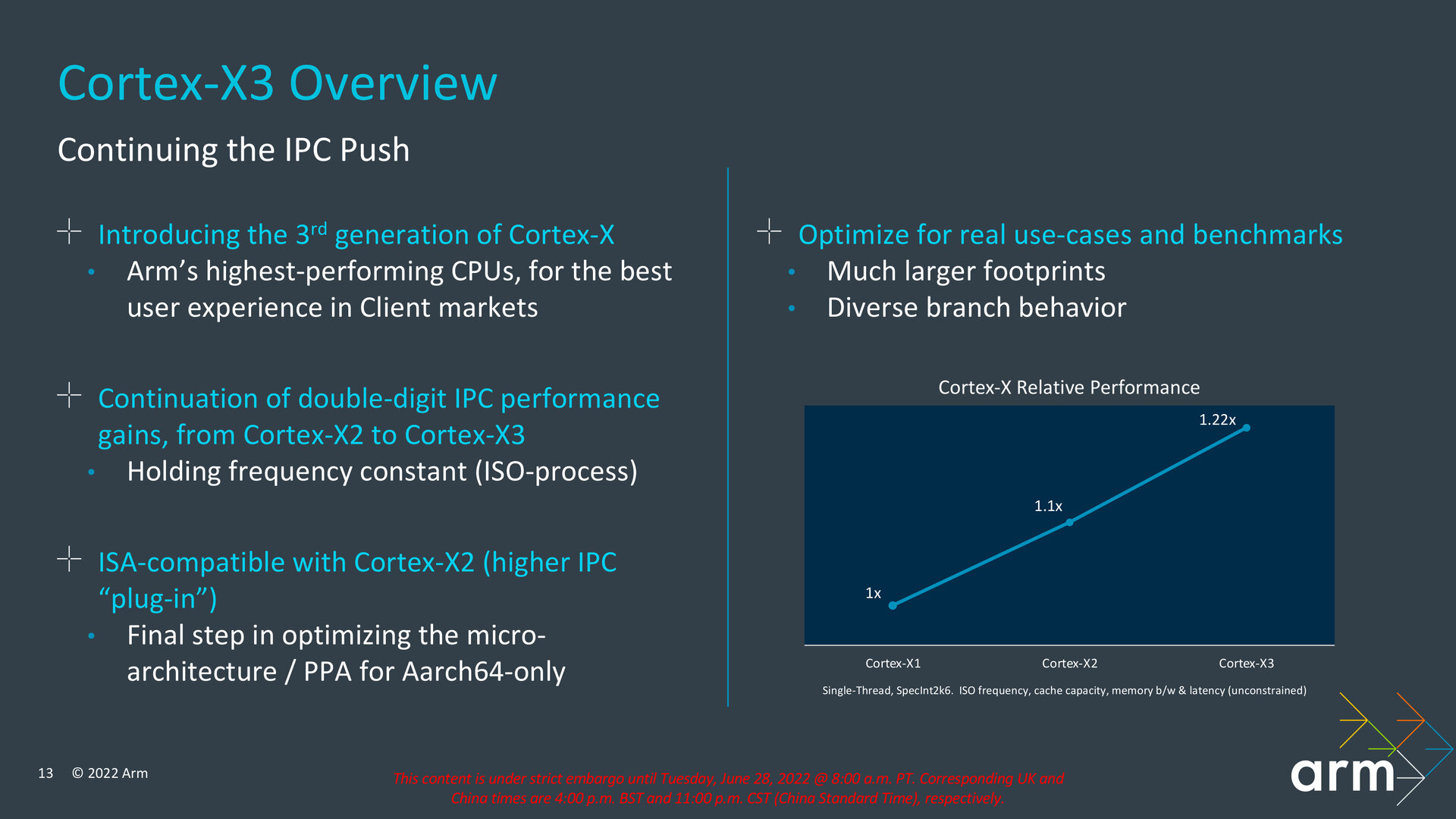
This 11% improvement should be a comparison with the Cortex-X2 at the same clock speed. At the same time, the Cortex-X3 should reach higher clock speeds. ARM gives an estimate that it could run at up to 3.3GHz in phones. According to ARM, at 3.3 GHz, the Cortex-X3 will achieve up to 25 % better single-threaded performance than the Cortex-X2 at 2.9 GHz. This is said to be a comparison on the same process, so the better clock speed is not just due to the use of better manufacturing technology, but also an architectural improvement.
However, although ARM here lists the clock speed of the previous Cortex-X2 core as just 2.9 GHz, there are faster implementations – Snapdragon 8+ Gen 1 has pushed the Cortex-X2 o 3.2 GHz thanks to transition to TSMC’s 4nm process. So when compared to that, the real clock speed increase would be lower and thus the overall increase would be less than that 25 %.

For reference, this could correspond to Geekbench 5 single-core score of somewhere between 1400 and 1500 points in smartphone SoCs. In higher-performance and higher-TDP laptop implementations, though, the Cortex-X3 could even reach up to 3.6 GHz, which would add extra single-core performance (Geekbench 5 single core might be around or just under 1600). ARM says that such a configuration would have up to 34 % better performance than what ARM has in laptops today (by which we means ARM processors outside of Apple’s silicon).
On the other hand, the increase in IPC by “only” 11 % is not that high in the context of the number of ALUs having increased from four to six. This might show that Cortex-X3 is somewhat of a basis for further development and only the next generations will probably get more benefit out of the much wider integer backend introduced in this generation, for example by further deepening the Reorder Buffer. It raises question whether ARM might have done better if they didn’t cut back so much on the uOP cache (though it’s true that Apple’s cores don’t use it at all). In any case, when future architectures enhance other aspects of the core, the ALUs added now will likely translate into greater IPC improvements.

In phones in 6–9 months, 12 cores for laptops?
These cores could hopefully appear in the upcoming next generation of phone processors, which could start coming out at the end of the year or at the turn of 2022 and 2023. The Cortex-X3 could appear in phones during the first half of 2023.
A very interesting news is that perhaps more powerful configurations could appear in laptops, where the SOCs would no longer have only one “prime” core of the X line. ARM says that an 8+4 configuration is now supported for the new generation of cores, where the processor would have eight large prime Cortex-X3 cores, plus four Cortex-A715 middle cores in place of little cores – actual no actual little Cortex-A510 cores would be used.
This could result in a very interesting multi-threaded performance, although single-threaded performance will obviously not improve (however, the 1600 points in Geekbench 5 with Cortex-X3 would already a be decent showing). But while ARM is envisioning this configuration, we don’t know yet whether manufacturers like Samsung, MediaTek or Qualcomm will really come up and adopt it for their laptop SoCs.
Sources: ARM, WikiChip, ComputerBase
English translation and edit by Jozef Dudáš, original text by Jan Olšan, editor for Cnews.cz
⠀


