





Když loni vyšly procesory Intel Rocket Lake s instrukcemi AVX-512, otestovali jsem při té příležitosti, jak s nimi dá zlepšit výkon ve video enkodéru x265. Protože nyní vydané procesory Ryzen 7000 s architekturou Zen 4 podporují AVX-512 také a u Rocket Lake se o výhodách a nevýhodách dost diskutovalo, vrátili jsme se k tehdejšímu testu a podíváme se, jak je na tom jeho alternativní implementace od AMD.
Náš loňský test AVX-512 vznikl víceméně náhodou. Nešlo o rozbor toho, jak dobré jsou tyto instrukce na tehdejších procesorech Intel Core i9 11. generace „Rocket Lake“ obecně. Dnes už to zní jako vzdálená minulosti, ale na jaře 2021 byly tyto procesory první mainstreamová CPU, která tyto „next-gen“ SIMD instrukce poskytovala běžným uživatelům mimo HEDT platformu X299, aby pak Intel za půl roku vydal 12. generaci Alder Lake a podporu AVX-512 si zase vzal zpátky.
Při testech Core i9-11900K, Core i7-11700KF a Core i5-11400F jsme tehdy narazili na to, že enkodér videa x265 dokáže sice AVX-512 použít ke zlepšení výkonu, ale ve výchozím nastavení to nedělá. Tehdejší článek byl napůl tip pro uživatele, jak to napravit a optimalizace využívající AVX-512 si u x265 ručně zapnout, a napůl rozbor, co to udělá s výkonem, ale i spotřebou.
Uběhl rok od Intelova obratu k big.LITTLE čelem, k AVX-512 zády, a po vydání Ryzenů 7000 nastala ironická situace. Toto instrukční rozšíření, které Intel dříve propagoval jako svou exkluzivní výhodu, teď takřka zachraňuje konkurenční AMD, které do architektury Zen 4 poprvé začlenilo podporu tohoto 512bitového vektorového rozšíření. Byť to zatím není podpora plnokulná, ale do značné míry konzervativní – Zen 4 používá pro výpočet většiny instrukcí staré 256bitové SIMD jednotky ze Zenu 3, takže jimi 512bitová operace musí projet na dvakrát.

Ryzen 7000, AVX-512 a x265 přijdou do baru…
Když už jsme ale loni tak trápili (a nezáměrně zprofanovali) Rocket Lake, vrátíme se teď ke stejnému testu, aby bylo vidět, jak se v něm blýskne implementace AVX-512 v Zenu 4. Opět je třeba upozornit, že to nebude nějaké rozsáhlé zhodnocení užitečnosti AVX-512 – jak jsme vysvětlovali v tehdejším článku, zrovna enkódování videa v x265 není úplně ideální pole pro využití AVX-512. Na jednu stranu sice takovéto multimediální úlohy umí krásně SIMD instrukce využít, ale není to u nich tak, že by zdvojnásobení vektoru automaticky vedlo k dvojnásobným FPS. Optimalizacemi se u nich dosahují vždy jen dílčí zlepšení, kdy se výkon zlepší třeba jenom o jednotky procent (a to se považuje za úspěch).
Pro připomenutí: s testovací konfigurací z našich recenzí, kde používáme výchozí nastavení Handbrake a x265 (jež AVX-512 ponechává nepoužité z historických důvodů, které jsme tehdy rozebírali), jsme u Rocket Lake po ručním zapnutí AVX-512 shledali zlepšení výkonu při stejné frekvenci o 7,5–9,0 %.
Špatná zpráva: Rocket Lake to šlo lépe
První nejzásadnější poznatek na začátek: AVX-512 u Zenu 4 pomáhá. Není to o moc, nárůst výkonu je jen +2,3 % u Ryzenu 9 7900X a u Ryzenu 5 7600X nám vyšlo ještě méně (tam šlo o rozdíl mezi 7,8 a 7,9 FPS, takže možná už je to trošku oběť zaokrouhlování statistik v x265 a ve skutečnosti je zlepšení na procenta o kapku bližší výsledku výkonnějšího modelu).
Jen pro připomenutí, v naší recenzi najdete nižší výsledek bez AVX-512. Je to kvůli tomu, aby byla metodika konstantní. Pokud kupujete procesor právě na enkódování a upravíte si nastavení x265 ručně, dostanete ještě tento bonus. Jak AVX-512 v rámci x265 zapnout? Návod najdete v loňském článku: Extra test Rocket Lake: jak použít AVX-512 v x265. A pomáhá to?
Ve srovnání s Rocket Lake je tedy třeba říct, že implementace Intelu pomáhala výkonu o dost víc. Je to proto, že ačkoliv klientské procesory Intelu mají slabší implementaci AVX-512 než serverové (a HEDT), trošku se jejich AVX-512 podceňuje. Reálně by totiž měl být rozdíl jen ve floating-point instrukcích FMA, pro které mají serverové procesory jednu 512bitovou FMA navíc, jež v klientských čipech včetně Ice Lake, Rocket Lake a Tiger Lake (a Alder Lake před umělým vypnutím podpory) chybí. Jenže enkódování videa a další multimediální úlohy používají celočíselné výpočty a permutace a v těch klientská implementace má výkon plný (toto je důležité a často se to ignoruje). Také její load/store pipeline mají pořád plnou šířku 512bitů.
Dobrá zpráva: AVX-512 na Zenu 4 pomáhá. To nebylo vůbec zaručené
Naproti tomu Zen 4provádí výpočty i celočíselných operací i floating-point operací s polovičním výkonem kvůli skutečně 256bitovým jednotkám a load/store pipeline majícím jen poloviční datovou šířku a tedy propustnost mezi registry a cache. Kvůli tomuto je vlastně hodně dobrá zpráva, že AVX-512 i tak pomáhá a výkon zvyšuje. Mohl by se totiž snadno stát opak – že by při použití AVX-512 optimalizací nakonec enkodér vyházel pomalejší, než kdyby procesor používal jen alternativní optimalizace pomocí 256bitových instrukcí AVX2. To, že místo toho vychází 2 % zrychlení, proto není neúspěch, ale potěšitelný výsledek.
To, že jen chabý výkonnostní zisk z AVX-512 považujeme u Zenu 4 za dobrou zprávu, má ještě jeden důvod. Vzpomeňte si totiž na Rocket Lake. Tam se s AVX-512 zlepšil výkon enkódování o 7,0–9,5 %, jenže spotřeba stoupla mnohem hůř (o 30 %). Efektivita tedy klesla a je otázka, jestli za takovou cenu vůbec to zrychlení chcete (někdy by třeba bylo efektivnější prosté přetaktování).
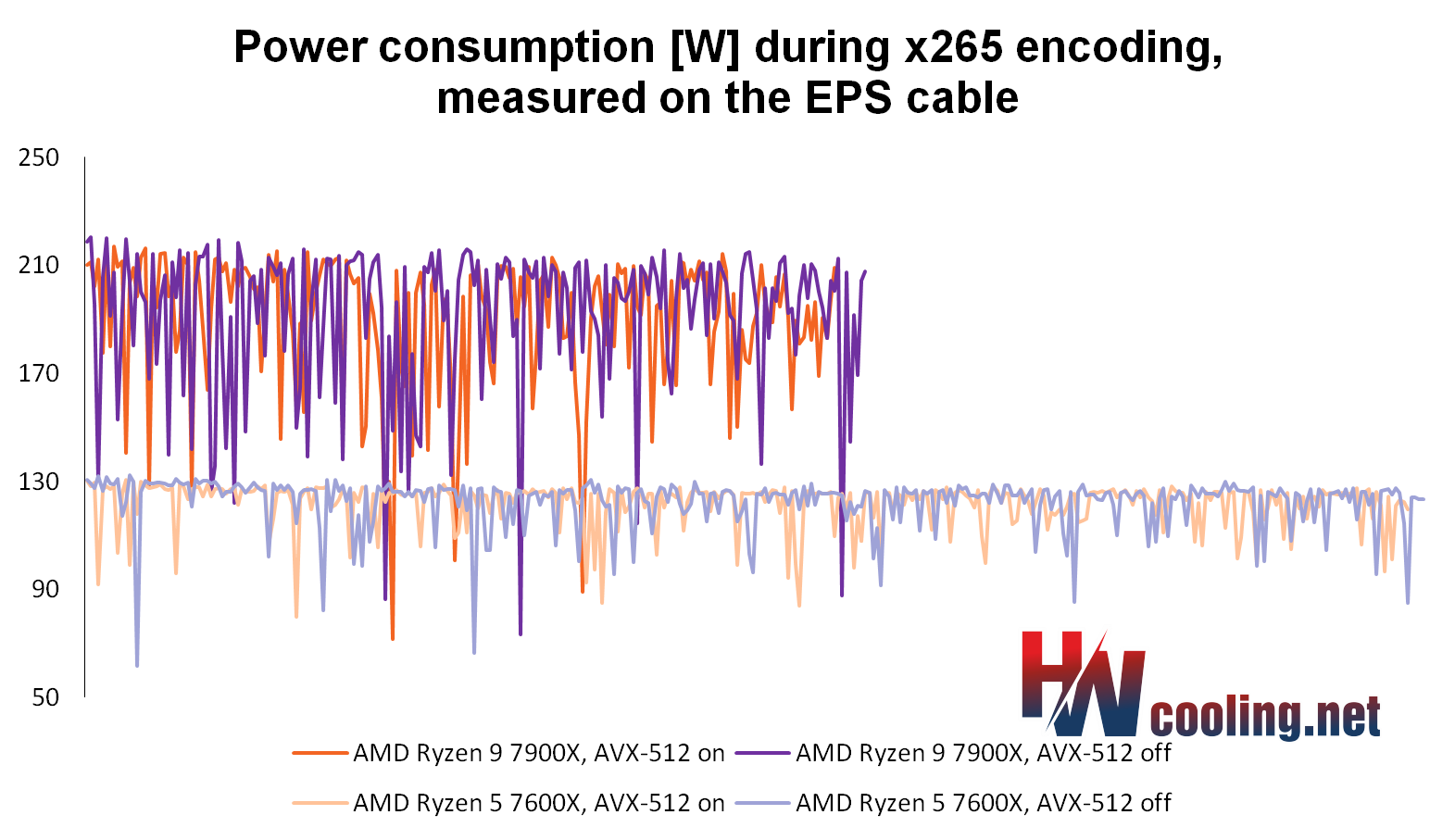
U Zenu 4 je spotřeba s AVX-512 paradoxně nižší…
Jenže u Zenu 4 s AVX-512 je spotřeba v podstatě stejná, takže menší zrychlení je úplně zadarmo a vždy má smysl AVX-512 nechat zapnuté. Respektive, pro pořádek musíme říct, že jsme testovali jenom jeden výkonnostní preset x265 a teoreticky je možné, že v jiném by to mohlo dopadnout jinak a teoreticky by se v nějakém mohla objevit regrese. Nicméně pokud už budete nějaký Zen 4 mít, můžete si snadno naměřit, zda vaše vlastní nastavení enkodéru z AVX-512 profituje, nebo ne.
…a frekvence vyšší
Ono je to dokonce tak, že nejenže u Zenu 4 instrukce AVX-512 spotřebu nezvyšují, ony ji dokonce o trošku snižují (a s tím se také nepatrně zlepší teploty). Procesory dokonce ze stejného důvodu patrně dosahují při používání AVX-512 o trošku vyšší frekvence. Snížení spotřeby dovolí jejich boostu nasadit v průměru lehce vyšší frekvence. Námi naměřené zlepšení výkonu není tedy čistě z toho, jak AVX-512 zvýšilo IPC, menší část je asi z vyšší frekvence.
Video je jedna věc, výkon v jiných aplikacích může být o dost lepší
Měly by ale každopádně existovat úlohy, kde bude Ryzenům 7000 (ale dost možná i Rocket Lake) podpora AVX-512 zvyšovat výkon mnohem víc, a už se ukázaly případy, kde to tak opravdu vypadá. Například web Phoronix na Ryzenech 7000 otestoval úlohy ze své rozsáhlé databáze linuxových benchmarků, a našel některé, které z AVX-512 profitují dost výrazně.
Malé zisky jsou v knihovně Dav1d (softwarová dekodér videa ve formátu AV1), což je multimediální kód asi podobný charakterem x265. Tam Phoronix naměřil díky AVX-512 zrychlení jen o +2,8–3,4 %. Ale v raytracingové knihovně Embree už nastalo zrychlení o +15,6 %. A v simdjson Phoronix dostal zrychlení o +14,0–32,6 %, což už je dost podstatný rozdíl (jde o knihovnu používající AVX-512 k zrychlení parsingu formátu JSON, což je úloha, kde byste potenciál pro SIMD optimalizace úplně nečekali).
AVX-512 vs. VNNI
Phoronix má v testu také výsledky, kde jsou nárůsty výkonu v ještě vyšších desítkách a dokonce stovkách procent. To jsou ale zřejmě případy, kde Zenu 4 nedodávají křídla instrukce AVX-512, ale VNNI určené pro akceleraci neuronových sítí (AI). Podobný případ máme i v naší metodice: jde o aplikace Topaz Labs (Gigapixel AI, Denoise AI atd.) Na ty se v budoucnu také podíváme, nyní k nim nebudeme odbíhat. Výsledky z Open VINO a podobných úloh teď tedy nechme stranou.
Na druhou stranu atypicky vysoké nárůsty výkonu jsou možné i u regulérního AVX-512. AnandTech například léta používal nestandardní vlastní benchmark, který měl záhadnou až podezřelou optimalizaci AVX-512 zvyšující výkon o brutální násobky. Šlo asi spíš o příklad, kdy standardní verze kódu používající AVX2 jednoduše nebyla dobře optimalizovaná a použití AVX-512 zvýšilo výkon ne ve skutečném smyslu, ale tím, že obešlo nějaký schovaný fatální bottleneck. Tento benchmark tak například vykazoval 5× zrychlení na procesorech Intel Cannon Lake v porovnání s jinak s téměř stejným jádrem Skylake (10nm Cannon Lake mělo mírně vyšší IPC a podporu AVX-512 v omezené klientské formě).
I na Zenu 4 má tato kuriozita docela famózní výkon. Tento test ale opravdu nepovažujeme za reprezentativní. Ani pro výkon Zenu 4 s AVX-512, ani pro aplikovatelnost AVX-512 jako takovou, což byly závěry, které bohužel občas na jeho základě byly činěné.
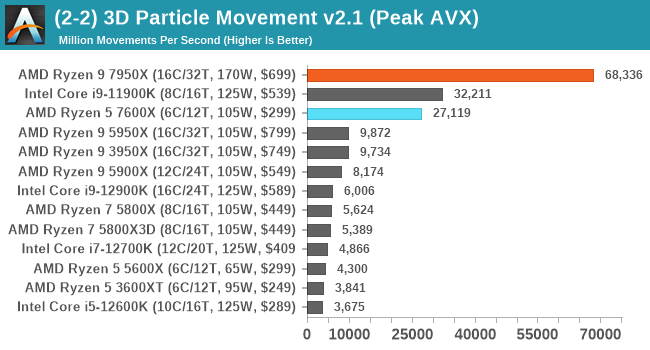
Akcelerace každopádně může být i s omezenou implementací AVX-512 dost úspěšná. Doufejme, že podpora ze strany AMD přiměje více vývojářů k tomu, aby tyto instrukce začali využívat (pro což ale možná bude nutné i to, aby je Intel vrátil do svých big.LITTLE klientských procesorů).
Proč jsou takty vyšší a spotřeba nižší?
První techničtější rozbor toho, jak se AMD implementace AVX-512 povedla, poskytl vývojář yCruncheru Alexander Yee. yCruncher dostal specifické optimalizace používající AVX-512 přímo vyladěné pro Zen 4 díky tomu, že AMD poskytlo jeho vývojáři ještě před vydáním hardware k testování.
Podle Alexandra Yee je důvod, proč AVX-512 zvyšuje dosažitelné frekvence a snižuje spotřebu, zřejmě v tom, že implementace AMD počítající instrukce AVX-512 na dva průchody na 256bitových jednotkách je energeticky efektivní. 256bitová SIMD jednotka v backendu (FPU) sice musí na 512bitové instrukci AVX-512 pracovat dva cykly, stejně jako kdyby se místo toho použily dvě 256bitové instrukce AVX2. Jenže rozdíl je v práci frontendu. Dvě instrukce AVX2 zaberou dvě místa v ROB, při dekódování a v dalších fázích počátečního zpracování kódu (a také je s nimi kód větší, takže se nemusí tak dobře vejít do L1i cache). Instrukce AVX-512 tuto zátěž frontendu sníží na polovinu. A toto může být znatelný zisk ve spotřebované energii, který sníží spotřebu procesoru při zpracování kódu přepsaného z AVX2 na AVX-512, což procesor Ryzen může využít k zvýšení frekvence.
„Implementace AVX-512 je nečekaně dobrá“
Zen 4 obsahuje všechny subsety AVX-512, které umí architektura Ice Lake od Intelu a navíc má podporu instrukcí BFloat16, kterou umí jen Intel Alder Lake a starší 14nm Xeony Cooper Lake. Chybí mu ale subsety AVX512_VP2Intersect (který umí Intel Tiger Lake) a AVX512_FP16 (poprvé v Alder Lake).
This is based on actual CPUID dump:https://t.co/Lt9aSXGbXu https://t.co/HWO8nWi1Ny pic.twitter.com/iVMGu3mk7q
— InstLatX64 (@InstLatX64) September 26, 2022
Podle Yeeho je implementace AVX-512 v Zenu 4 nečekaně kvalitní, ačkoliv používá dvouprůchodové pracování pomocí 256bitových jednotek. Většina operací je rychlých (nemají nějaké špatné latence), a také propustnost co dopočtu 512bitových instrukcí zpracovaných za cyklus je dobrá v rámci toho, že se používají 256bitové jednotky. AMD má obzvlášť rychlé operace Conflict Detection a práci s Mask Registry, která je výrazně výkonnější než u Intelu. Velmi výkonné je celočíselné 64×64 násobení (vmpmullq).
Naopak horší než u Intelu (mimo výpočetní kapacity dané 256bitovými jednotkami a load/store) jsou operace Compress (vcompressd). Špatný je výkon Scatter/Gather, což je ale i případ Intelu, jen v menší míře.
Ne všechno je na dva průchody: 512bitová shuffle jednotka
Ačkoliv obecně lze říci, že implementace AVX-512 má poloviční výkon proti hypotetické 512bitové verzi kvůli dvouprůchodovému 256bitovému zpracování, v jedné oblasti to neplatí a Zen 4 má výkon plnotučný: v permutacích (shuffle instrukcích). AMD totiž implementovalo plně 512bitovou shuffle jednotku, která s plným výkonem provádí všechny 512bitové shuffle instrukce (jako bonus ale také tato jednotka umí provést dvě 256bitové shuffle instrukce AVX2 za cyklus). Zejména včetně těch, které překračují jednotlivé 128bitové a 256bitové segmenty vektoru. Permutační instrukce právě kvůli tomuto překračování nelze jednoduše provádět rozdělené ve dvou průchodech na 256bitovýh jednotkách jako běžné počítací operace. Pokud by AMD použilo staré 256bitové jednotky, byl by výkon těchto instrukcí dost slabý (měly by latenci mnoho cyklů).
Permutační instrukce jsou pro mnoho algoritmů a optimalizací kritické, takže zde AMD udělalo hodně dobrou věc. Jde možná o jeden z klíčových faktorů v tom, proč AVX-512 na Zenu 4 pomáhá. Když například AMD implementovalo AVX2 dvouprůchodově na 128bitových jednotkách v Zenu 1, shuffle jednotka takto nativní nebyla a její výkon byl proto celkem špatný, což omezilo přínos podpory AVX2.
Rozbor Alexandra Yee si můžete celý přečíst zde na MersenneForum. Pokud máte o problematiku AVX-512 zájem, nelze ho nedoporučit (a pro programátory bude asi užitečnější než náš článek…).
yCruncher: +4–12 %
Přímo v rámci našeho testování jsme pro vás yCruncher vyzkoušeli. Jeho optimalizace využívající AVX-512 jsou přítomné ve verzi v0.7.10.9513, kterou jsme otestovali na Ryzenu 5 7600X a Ryzenu 9 7900X.
A oproti starší verzi v0.7.10.9507, která takto optimalizovaná není a AVX-512 na Ryzenech 7000 nepoužívá, je už nárůst na 7600X o něco vyšší než v x265, o téměř +4 %. Připomeňme, že to je bonus zadarmo. Zvláštní výjimka nastala nicméně na Ryzenu 9 7900X v mnohovláknovém režimu, kde jsme z nějakého důvodu naměřili mnohem větší zrychlení (+12 %). Těžko říct proč, ale náhoda to není, stejně to vyšlo při opakovaných kontrolách.
I v tomto případě v naší recenzi najdete výsledky yCruncheru se starší verzí, takže ve skóre pozitivní vliv AVX-512 není započítán. Je to opět kvůli tomu, že udržujeme metodiku konstantní kvůli konzistenci. Jinak by mohlo dojít k tomu, že se při aktualizaci programu nepředvídatelně změní výkon a výsledky přestanou být srovnatelné s výsledky procesorů z předchozích testů. Čistě pro zhodnocení toho, jak se architektura Zen 4 povedla, si ale můžete pár bodíků za rychlejší x265 a yCruncher v duchu připočítat.
Tip: Test AMD Ryzen 9 7900X: Medzigeneračný skok ako HROM
Zdroje: HWCooling, Cnews, Phoronix, MersenneForum, AnandTech
Jan Olšan, redaktor Cnews.cz
⠀⠀




