





When Intel Rocket Lake processors with AVX-512 instructions came out last year, we took the opportunity to test how they can improve performance in the x265 video encoder. Since the now-released Ryzen 7000 processors with Zen 4 architecture also support AVX-512, and there has been a lot of debate about the pros and cons with Rocket Lake, we went back to that test to see how AMD’s alternative implementation fares in it.
Our AVX-512 test last year happened more or less by accident. It was not supposed to be an analysis of how good these instructions were on the then 11th generation Intel Core i9 “Rocket Lake” processors in general. It kind of sounds like the distant past today, but in the spring of 2021 these CPUs were the very first mainstream CPUs to provide these “next-gen” SIMD instructions to mainstream users outside of the HEDT X299 platform, only to have Intel flip by releasing the 12th generation Alder Lake and take the AVX-512 support back six months later.
While testing the Core i9-11900K, Core i7-11700KF and Core i5-11400F back then, we found that the x265 video encoder can use AVX-512 to improve performance, but it does not actually do so by default. The article at the time was simultaneously a tip for users on how to fix this and manually enable AVX-512-using optimizations in x265, and an analysis of what it does to performance as well as power draw.
It’s been a year since Intel’s pivot from AVX-512 to big.LITTLE and we are in an ironic situation after the release of the Ryzen 7000. You could almost say that rival AMD is now saving this instruction set extension, which Intel had previously touted as its exclusive advantage, through incorporating support for the 512-bit vector extension into their new Zen 4 architecture – for the first time in the history of the competing x86 vendor. Even though it’s not full support yet and AMD opted for a more conservative approach, where Zen 4 uses the old 256-bit SIMD units from Zen 3 to execute most instructions, so a 512-bit operation has to be run through them in two passes (this is also being referred to as double-pumping 256-bit units).

Ryzen 7000, AVX-512 and x265 walk into a bar…
But since we gave Rocket Lake such a hard time last year, we’ll go back to the same benchmark to see how the AVX-512 implementation in Zen 4 performs. Again, it should be noted that this won’t be some sweeping assessment of AVX-512’s usefulness – as we explained in that previous article, video encoding in x265 isn’t exactly an ideal field for AVX-512 usage. On the one hand, such multimedia tasks can make beautiful use of SIMD instructions, but it’s not like doubling the vector automatically leads to double FPS. Optimizations for these always only yield small additive improvements, where performance improves by perhaps only a few percent (and this is considered an achievement).
As a reminder: using the test configuration from our regular reviews using the default Handbrake and x265 settings (which leave AVX-512 unused for historical reasons we discussed in the Rocket Lake article), we have found a 7.5-9.0 % improvement in performance at the same clock speed for Rocket Lake after manually enabling the AVX-512.
The bad news: Rocket Lake did better
The first most important observation to start with: AVX-512 does help with Zen 4. It’s not by much, the performance increase is only +2.3 % on the Ryzen 9 7900X, and we got even less on the Ryzen 5 7600X (there it was a difference between 7.8 and 7.9 FPS, so maybe this result is a bit of a victim of reported stats rounding done by x265, and in fact the percentage improvement is a touch closer to the result of the higher-performance model).
Just as a reminder, in our review you will only find the lower result without AVX-512. This is to keep the methodology constant. If you are looking for a processor for encoding and adjust the your x265 settings manually, you still get the extra bonus.
Looking for how to enable AVX-512 within x265? See last year’s article for instructions: Intel AVX-512 tested in x265: how to enable it and does it help?
So compared to Rocket Lake, it has to be said that Intel’s implementation helped performance a lot more. This is because although Intel’s client processors have a weaker AVX-512 implementation than server (and HEDT) processors, their AVX-512 is usually a bit underrated by people. Realistically, the only difference should be in the floating-point FMA instructions, for which server processors have one extra 512-bit FMA pipe, which is missing in client chips including Ice Lake, Rocket Lake and Tiger Lake (and and Alder Lake before support was artificially disabled). But video encoding and other multimedia tasks use integer operations and permute (shuffle) ops, and in those the client implementation actually has full performance (this is important and often ignored). Also, even the client cores’ load/store pipelines are still a full 512 bits wide.
The good news: AVX-512 on Zen 4 helps. This was not at all guaranteed
In comparison, Zen 4 executes both integer operations and floating-point operations with half the performance due to truly having just 256-bit units and its load/store pipelines having only half the data width and the half the bandwidth between registers and cache. Because of this, it is actually great news that AVX-512 still helps and improves performance. In fact, it was entirely expected that the opposite could happen – that the encoder would end up coming out slower when using AVX-512 optimizations compared to when the processor only uses alternative optimizations using 256-bit AVX2 instructions. Therefore, the fact that there’s a 2 % improvement instead is a pleasing result rather than a let-down.
There’s another reason that has us consider the merely meager performance gains from the AVX-512 to be good news with the Zen 4. Remember the Rocket Lake situation. There, the encoding performance improved by 7.0–9.5 % with AVX-512, but the power draw went up much more (by 30 %). So the efficiency went down, and it’s questionable whether you even want that improvement at that price (sometimes, maybe a simple overclock would be more efficient).
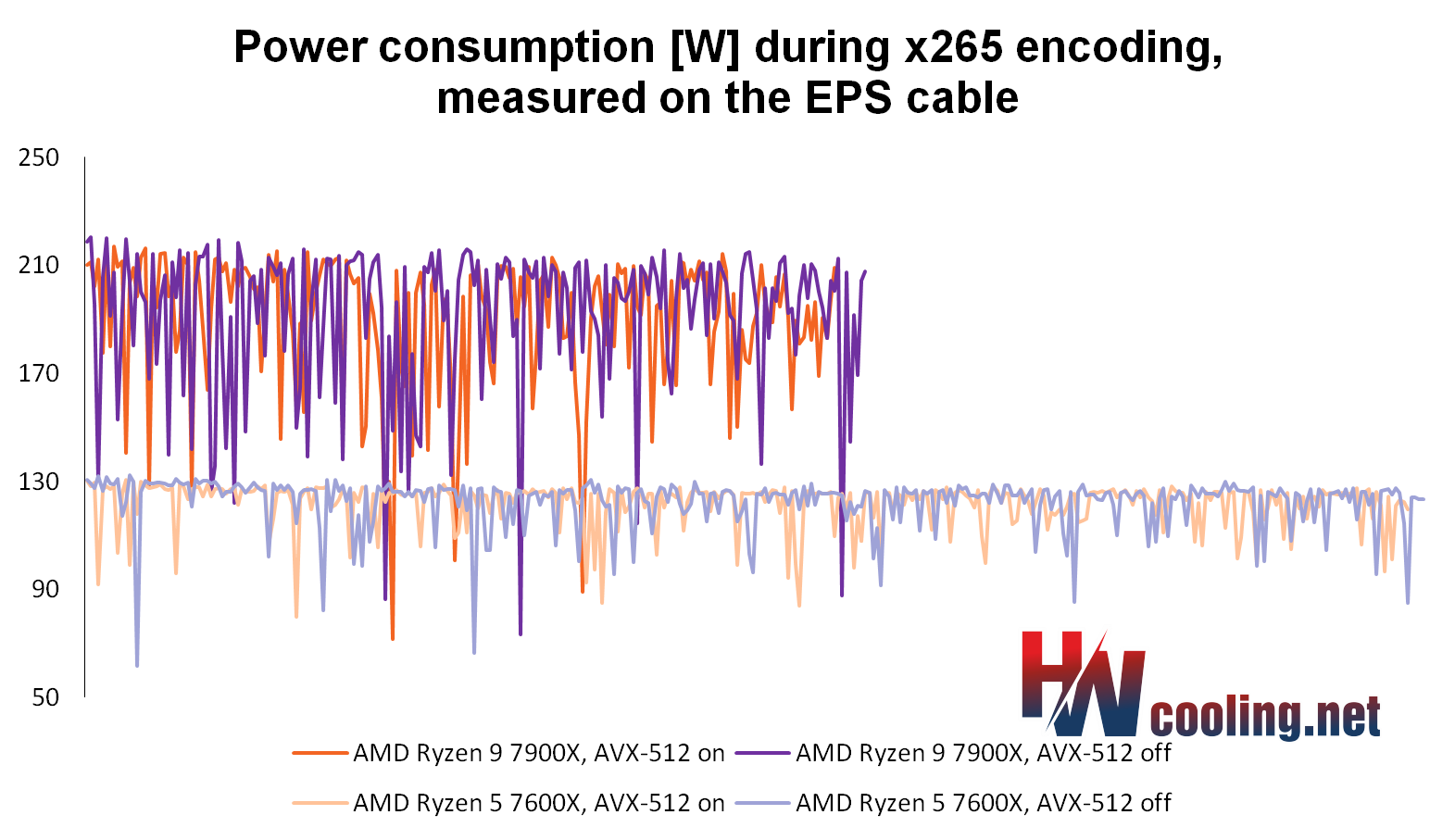
On Zen 4, AVX-512 ironically makes the power draw lower…
But when using AVX-51 on Zen 4, the power draw is basically the same, so that minor improvement comes completely free and it’s always worthwhile to leave AVX-512 on. To be fair, for the sake of clarity, we have to say that we only tested one x265 performance preset and it is theoretically possible that with a different one, the performance could turn out differently and theoretically there could be regression in some other scenarios. However, if you buy a Zen 4 CPU, you will be able to easily measure whether or not your own encoder setup benefits from the AVX-512.
…and the clock speeds higher
Actually, it’s not just that AVX-512 instructions do not increase the power draw of Zen 4, they actually reduce it a little (and with that, the temperatures are slightly improved too). The processors even achieve a slightly higher clock speed when using AVX-512, for the same reason. The reduction in power draw allows their boost to ramp to slightly higher clock speeds on average. So our measured performance improvement is not purely from the AVX-512 increasing the IPC, a smaller part is probably from that higher clock speed.
Video is one thing, performance in other applications can be much better
However, there should be tasks where AVX-512 support will give Ryzen 7000 (but quite possibly Rocket Lake as well) a much bigger performance boost than this, and there are already cases where it is really demonstrated. For example, the Phoronix site tested tasks from its extensive database of Linux benchmarks on Ryzen 7000s, and found some programs that benefit quite significantly from AVX-512.
In the Dav1d library (a software video decoder for the AV1 format), which is a multimedia code probably similar in nature to x265, there are again just small gains. There, Phoronix measured a improvement of only +2.8–3.4 % thanks to the AVX-512. But the Embree ray-tracing library has seen an improvement of as much as +15.6 %. And in simdjson, Phoronix got a improvement of +14.0–32.6 %, which is already a pretty significant difference (it’s a library using AVX-512 to speed up JSON parsing, a task where you wouldn’t quite expect the potential for SIMD optimizations).
AVX-512 vs. VNNI
Phoronix also has test results where performance increases are even higher, in high tens and even hundreds of percents. However, these seem to be cases where Zen 4 is not reaping the benefits of AVX-512 instructions, but instead benefiting from the VNNI instructions designed for neural network (AI) acceleration. We have a similar case in our methodology: the Topaz Labs applications (Gigapixel AI, Denoise AI, etc.) We will also look at these in the future,so we will not digress to them now. So let’s leave the results from Open VINO and similar tasks aside for now.
On the other hand, some atypically high performance gains are possible even with the regular AVX-512 subsets. For example, AnandTech has long been using a non-standard custom benchmark with mysterious (or even suspicious) AVX-512 optimizations that are increasing performance multiple times. This was probably more of an example where the standard version of the code using AVX2 was simply not well optimized, so using AVX-512 probably increased the performance through bypassing some fatal hidden bottleneck, rather than speeding things up in the usual sense. For example, this benchmark showed a 5× improvement even on Intel Cannon Lake processors compared to an otherwise nearly identical Skylake core (10nm Cannon Lake was just a slightly higher-IPC evolution of Skylake, besides adding AVX-512 support in limited client form).
Even for Zen 4, this oddity of a benchmark shows quite the remarkable performance. But we really don’t consider this test to be representative – neither of AVX-512 performance of the Zen 4 core, nor for the applicability of the AVX-512 per se, which were the conclusions that were unfortunately sometimes drawn from its results.
To sum it up, software acceleration can be quite successful even with a limited AVX-512 implementation like this. Hopefully, AMD’s support will get more developers to start using these instructions (which may however also require Intel to put them back into their big.LITTLE client processors).
Why are clock speeds higher and power draw lower?
The first more technical analysis of how AMD’s AVX-512 implementation fares was provided by yCruncher developer Alexander Yee. yCruncher received specific optimizations using AVX-512 directly tuned for Zen 4 thanks to AMD providing its developer with hardware for testing prior to release.
According to Alexander Yee, the reason why AVX-512 increases the achievable clock speeds and reduces power draw is probably because AMD’s implementation executing AVX-512 instructions in two passes via 256-bit units is actually power efficient. On one hand, the 256-bit SIMD unit in the backend (FPU) has to spend two cycles on a 512-bit AVX-512 instruction, the same as when two 256-bit AVX2 instructions are used instead. But there is a difference in how the frontend is affected. The two AVX2 instructions take up two entries in the ROB, during decoding and at other stages of the initial code processing throughout the processor’s pipeline (and they also make the code bigger with them, so it may not fit as well in the L1i cache). The AVX-512 instructions halve this load on the frontend. And this can be a noticeable improvement in power consumed, reducing the CPU’s overal power draw when processing code that is converted from AVX2 to AVX-512. And the Ryzen processor can use this energy saving to increase clock speed.
“The AVX-512 implementation is unexpectedly good”
Zen 4 includes all the AVX-512 subsets that Intel’s Ice Lake architecture offer, plus it has support for BFloat16 instructions that only Intel Alder Lake and older 14nm Cooper Lake Xeons provide. However, it lacks the AVX512_VP2Intersect subsets (which Intel Tiger Lake can do) and AVX512_FP16 (first present in Alder Lake).
https://twitter.com/InstLatX64/status/1574401603133575169
According to Yee, the AVX-512 implementation in Zen 4 is unexpectedly good, despite relying on the double pumping of 256-bit units. Most of the operations are fast (they don’t have bad latencies), and the bandwidth in terms of 512-bit instructions processed per cycle is also good in the context of using 256-bit units. AMD has particularly fast Conflict Detection operations and Mask Registry handling, which has significantly higher perfomance than Intel’s implementation. Integer 64×64 multiplication (vmpmullq) is extremely fast too.
On the other hand there are some instructions that perform much worse than what is necessitated by the use of 256-bit units and 256bit load/store. That is a case with Compress (vcompressd) operations and Scatter/Gather performance is also poor. Scatter/Gather is also not great on Intel, but to a lesser extent.
Not everything is double-pumped: 512-bit shuffle unit
Although it can generally be said that Zen 4’s AVX-512 implementation has half the performance of a hypothetical fully 512-bit version due to the double-pumped 256-bit processing, there is one area where this is not true and Zen 4 has full performance: in permutes (shuffle instructions). This is because AMD has implemented a fully 512-bit shuffle unit that executes all 512-bit shuffle instructions with full performance (but as a bonus, this unit can also split its resources to execute two 256-bit AVX2 shuffle instructions per cycle). In particular, this is including those shuffles that cross individual 128-bit and 256-bit vector segments (lanes). Permutation instructions, precisely because of this lane-crossing, cannot simply be executed split in two passes on a 256-bit unit like the normal compute operations. If AMD were to use the old 256-bit units even for shuffle ops, the performance of these instructions would be quite poor (they would have a latency of many cycles).
Permutation instructions are critical to many algorithms and optimizations, so AMD has made a good choice here. This is perhaps one of the key factors in why AVX-512 on Zen 4 helps. For example, when AMD implemented AVX2 in a similar fashion in Zen 1, using double-pumping off 128-bit units, the shuffle unit was not native in this way. As a result, the performance was quite poor, limiting the benefit of AVX2 support on that core.
You can read Alexander Yee’s analysis in full here on MersenneForum. If you are interested in the AVX-512, we simply have to recommend it (and for software developers, it will probably be much more useful than this article of ours…).
yCruncher: +4–12 %
As part of our benchmarking, we put yCruncher to the test for you. Its optimizations using AVX-512 are present in v0.7.10.9513 version, which we tested on Ryzen 5 7600X and Ryzen 9 7900X.
And compared to the older v0.7.10.9507 version, which is not optimized in this manner and does not use AVX-512 on Ryzen 7000, the increase on 7600X is slightly higher than in x265, the performance goes up by almost +4 %. Let us reiterate that this is a free bonus. However, a peculiar outlier result occurred on the Ryzen 9 7900X in multi-threaded mode, where for some reason we measured a much higher improvement (+12 %). It’s hard to say why, but it’s not a coincidence, it came up the same on repeated test runs, too.
Again, you will only find yCruncher results taken with the older version in our regular review, so the positive influence of AVX-512 is not counted in its score. This is because we keep the methodology constant for consistency. Otherwise, there would be a risk that performance changes unpredictably when a program in the test suite is updated, making the results no longer comparable to the results of CPUs from previous tests. But if you just want to know how well is the Zen 4 architecture performing, you can mentally add a few points for the faster x265 and yCruncher.
Read more: AMD Ryzen 9 7900X test: A BANG of an intergenerational leap
Sources: HWCooling, Cnews, Phoronix, MersenneForum, AnandTech
English translation and edit by Jozef Dudáš
⠀






Interesting analysis. I was curious how AMD’s AVX-512 would compare to Intel’s, especially since Zen 4 uses 256-bit units. The fact that power draw doesn’t increase is a nice surprise. For those looking to test their own setups, Gameilo – Free Online Browser Games offers a fun distraction while benchmarking.
Hmm, does Gameilo support AVX-512 instructions, or what’s the connection there? 🙂
Interesting to see how AVX-512 performs on Zen 4. The 2% improvement in x265 is modest but impressive considering the 256-bit units. For tasks like JSON parsing, the gains are much larger. I’ve been looking into tools that leverage such optimizations, like aihair.dev-ai hair design, which also uses advanced processing.
Do you happen to have any results available showing how AI Hair benefits from AVX-512 instructions? 🙂