




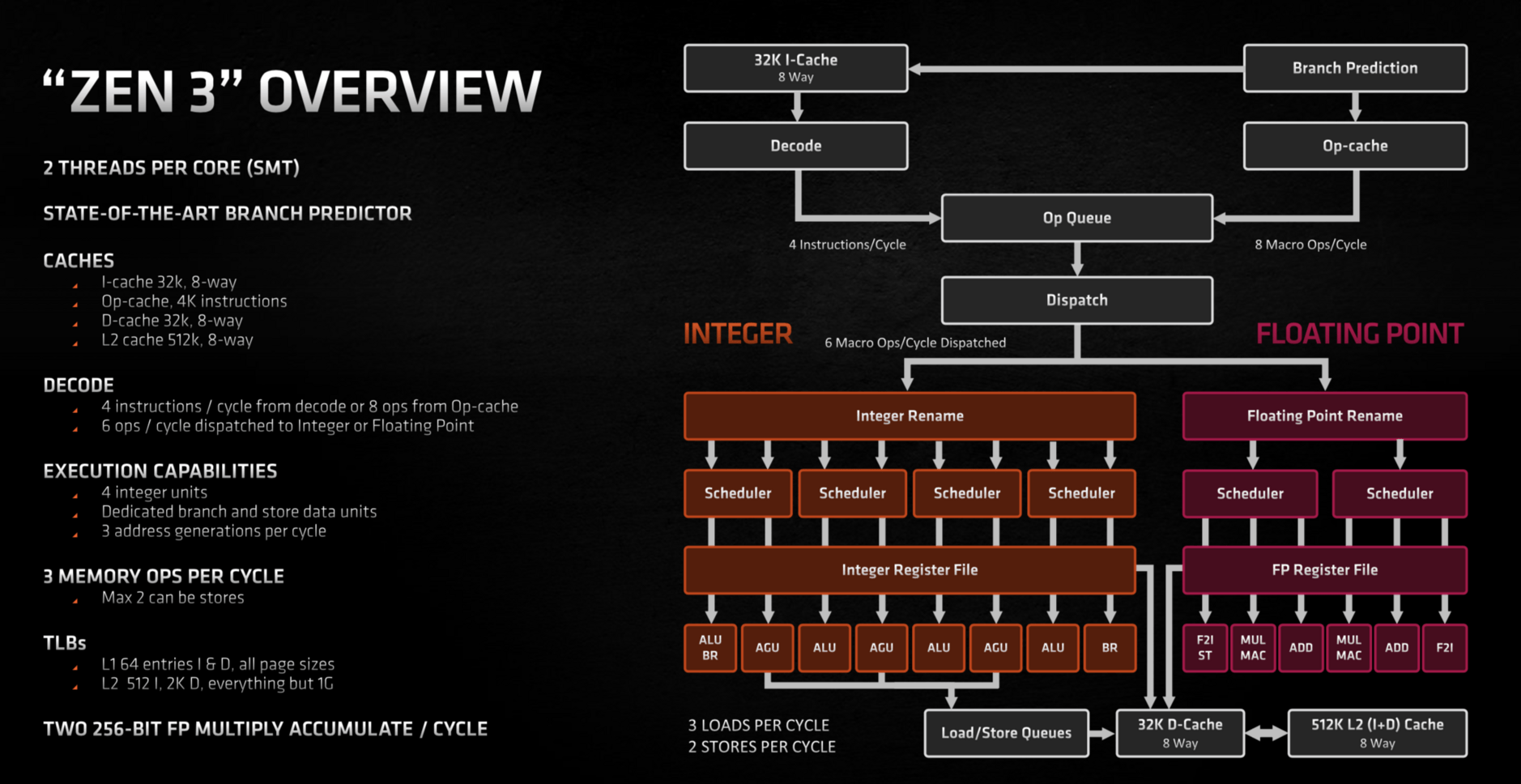
AMD Zen 3: nová architektura, Op cache a frontend
Minulý měsíc AMD vydalo procesory Ryzeny 5000. Jejich architektura Zen 3 přinesla nakonec možná víc, než se čekalo, výkon na 1 MHz někde převyšuje i IPC nejnovějšího jádra Intelu Willow Cove (Tiger Lake). Zen 3 je podle AMD jeho největší překopání architektury od vůbec prvního Zenu, pročež se podíváme, jaké změny v něm inženýři provedli, aby dokázali porazit Intel i v jednovláknovém a herním výkonu.
Ryzen 5000 je vyráběný 7nm procesem N7 od TSMC. Nemělo by jít o proces N7+ s EUV a zřejmě ani o vylepšenou ne-EUV verzi N7P. Respektive to platí pro tzv. CPU čiplety. Zen 3 však v desktopovém a serverovém provedení přebírá stejnou koncepci jako měl Zen 2. Jádra CPU a jejich propojovací logika plus L3 cache se nachází v malých 7nm křemících (i když s plochou 80,7 mm² větších, než u Zenu 2) tvořených 4,15 miliardami tranzistorů, které se připojují k 12nm „IO čipletu“, který zase obsahuje konektivitu, řídící logiku a zejména řadič pamětí.
Nyní představené desktopové Ryzeny 5000 „Vermeer“ mají tento IO čiplet převzatý z Ryzenů 3000 „Matisse“, takže změny v architektuře jsou víceméně izolované jen do samotných CPU jader a jejich infrastruktury v CPU čipletech. Toto nejspíš bude platit i pro serverový Epyc 7003 „Milan“, jenž asi také bude přejímat IO čiplet z Epyců 7002. Ale pro notebooky by z kraje roku 2021 mělo AMD vydat notebookové APU „Cezanne“, které bude celé monoliticky 7nm a bude mít jádra Zen 3 také. U něj tedy možná nastanou i nějaké další změny. Zatím se ale budeme věnovat Zenu 3 v té podobě, v jaké ho používají procesory Vermeer (tedy AM4 Ryzeny bez integrovaného GPU).
Podle informací, které AMD sdělilo novinářům, je Zen 3 novou architekturou, i když ne bez návaznosti na předchůdce. Zatímco Zen 2 poměrně úzce navazoval na Zen 1 a rozvíjel ho, Zen 3 je výraznější redesign (který by asi zase mohl být dál rozvinutý v Zenu 4). Většina součástí byla údajně aktualizována či se výrazně změnila jejich implementace, i když celková koncepce se dle schémat nezdá zas tak moc odlišná. Je zajímavé, že jádro dosahuje poměrně velkého zvýšení IPC (dejme tomu cca 13–19 % podle měření), ačkoliv nedošlo k nějakému na první pohled patrnému „rozšíření“. Zen 3 pořád dekóduje maximálně čtyři instrukce za cyklus a má také jen čtyři ALU (proti šesti u ARM jader Applu), recept na výkon je tu tedy trochu jiný.

Op Cache místo více dekodérů
Pokud budeme sledovat cestu instrukcí v pipeline procesoru, začneme tzv. frontendem, kde dochází ke zpracování instrukcí před samotnými výpočty. Jak už bylo řečeno, Zen 3 má stále beze změn čtyři dekodéry instrukcí, které zpracovávají instrukce po „fetchi“ z instrukční L1 cache. Pokud jste studovali diskuze o nových ARM procesorech Apple, možná jste narazili na názor, že právě v dekodérech je fatální slabina architektury x86, protože její komplexnost a variabilní délka instrukcí (proti uniformně 32bitovým instrukcím ARM) znemožňuje efektivní paralelizaci procesu dekódování instrukcí – někde se například objevuje (ne úplně podložený) názor, že u x86 je téměř nemožné mít víc než čtyři dekodéry (zpracovávající čtyři instrukce/cyklus).
Komplikace je u x86 v tom, že kvůli nepředvídatelné délce instrukcí není triviálně jasné, kde jednotlivé instrukce začínají (toto lze ovšem řešit předdekódováním hledajícím jejich začátky a Intel už mimochodem má jádra s pěticí dekodérů).
Současné procesory x86 ovšem řeší obtížnější dekódování jinak než dalším přidáváním dekodérů, což platí i pro Zen 3: pomocí tzv. Op Cache (Intel stejné řešení má již od Sandy Bridge). To je cache pro uložení výsledku již dekódovaných instrukcí, z níž například ve smyčkách, kdy se kód opakuje, procesor přebírá dekódované instrukce místo toho, aby kód opět procházel dekodéry. Ona nejobtížnější část procesu pro instrukční sadu x86 se tedy při nalezení potřebných operací v Op cache zcela přeskočí. Tato cesta je energeticky méně náročná i a výkonnější – do dalšího zpracování může jít u Zenu 3 až osm operací za jeden cyklus, zatímco z dekodérů samotných jen ty čtyři.
Procesory x86 počítají s tím, že majoritu času (i když ne úplně vždy) poběží právě z Op cache, ne přes klasické komplexní dekódování. Na toto je proto třeba při poměřování s jádry ARM myslet (dlužno říci, že nejnovější Cortexy už mají Op cache také, ačkoliv Apple ji nepoužívá).
Vylepšená OP Cache
AMD Zen měl kapacitu Op cache 2000 instrukcí, což Zen 2 zvětšil na 4000 (ale z cenu toho, že se zase zmenšila instrukční L1 cache z 64 na 32 KB, bylo to tedy něco za něco). Zen 3 ponechává kapacitu stejnou a také výstup 8 operací za cyklus se nezvýšil.
Ale přes stejné papírové parametry má být výkon lepší, například v situacích, kdy sekvence instrukcí přechází z jednoho režimu do druhého. Zen 3 má mít rychlejší přepínání režimů mezi klasickým dekódováním a „zkratkou“ přes Op cache a přepínání má vyšší granularitu. Přehození výhybky mezi plným dekódováním a a recyklací operací z cache asi není úplně triviální, takže eliminací zpoždění a zpomalení při přepnutí lze asi získat zpět nějaký předtím ztracený výkon.
Změny v této části údajně samy o sobě zvýšily IPC jádra asi o 2,7 % (proti Zenu 2) z těch 19 %, které AMD uvádí jako celkové zlepšení výkonu na 1 MHz.
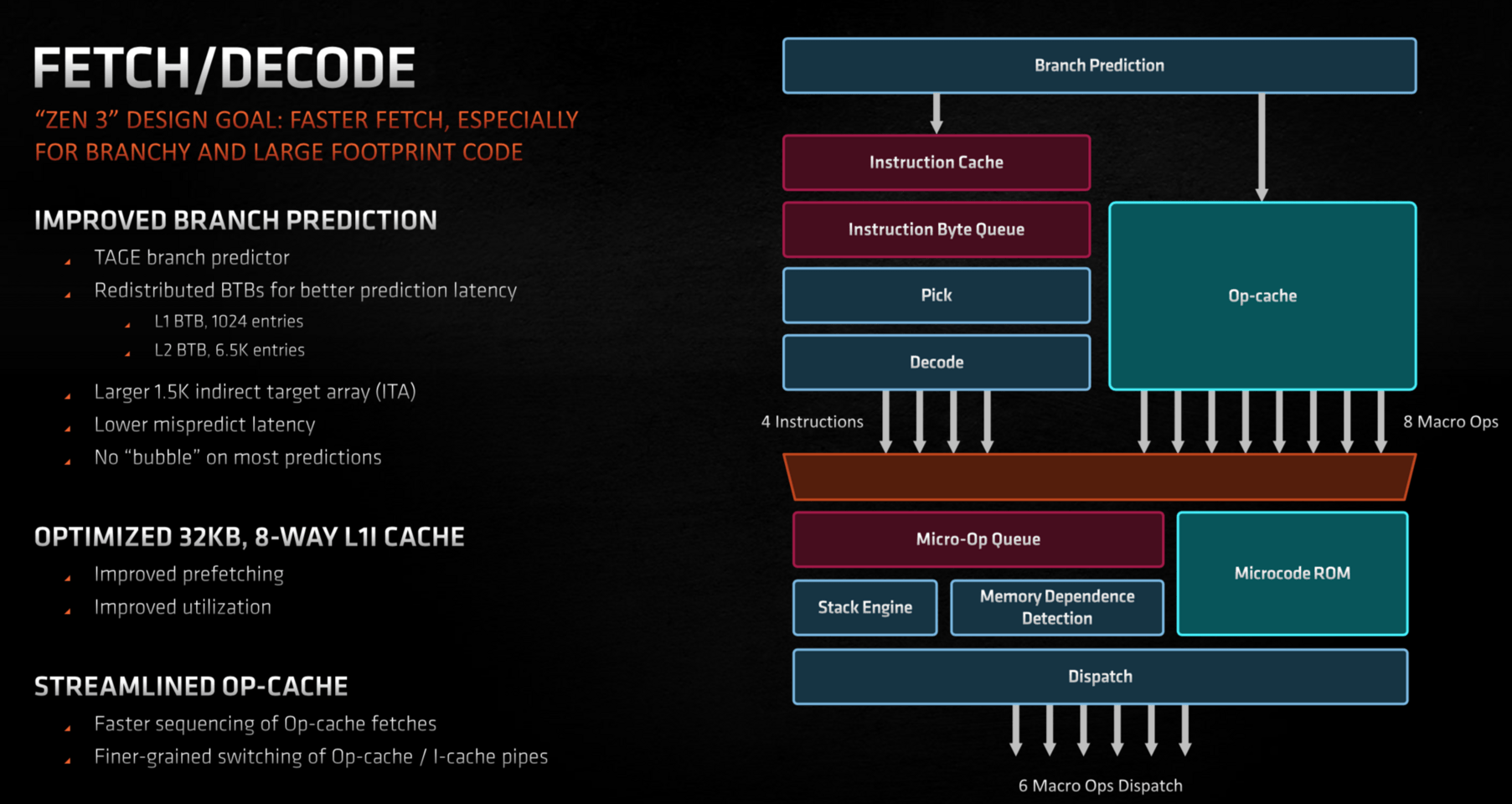
Také instrukční cache, z které proudí instrukce pro klasické dekodéry v případě kompletního nezkráceného zpracování, má být efektivnější, ačkoliv má stejné parametry – kapacita je stejných 32 KB s osmicestnou asociativitou jako u Zenu 2. Ovšem prefetch kódu z L2 cache byl vylepšen a také využití kapacity L1 instrukční cache má být účinnější.
Ať už dekódované instrukce („opy“) jdou z instrukční cache přes dekodéry nebo z Op cache, zařazují se do fronty operací (Op Queue), z níž fáze Dispatch posílá operace k vykonávání. Dispatch umí poslat dál maximálně šest operací za cyklus, což limituje maximální výkon jádra na tuto úroveň. Ačkoliv z Op cache může jít dál až osm operací za cyklus, toto slouží asi hlavně k rychlejšímu naplnění fronty například po špatné predikci, kdy se musí dohánět. Vyšší propustnost Op cache také vyvažuje to, že standardní dekodéry umí jen čtyři instrukce, což by zase bylo pod rychlostí umožněnou dispatchem. Vyšší propustnost, když se berou instrukce z Op Cache, by to v průměru měla kompenzovat.
Vylepšená predikce větvení
Ve frontendu je ještě velmi důležitým faktorem prediktor větvení, jenž reálně běží ještě před dekódováním a fetchem a snaží se uhádnout, kterým směrem se při větvení vydá běh programu, aby nebylo nutné čekat na vyhodnocení podmínky, což by způsobilo velké prostoje. Místo toho se na základě odhadu ihned spekulativně počítá dál a pokud by odhad nevyšel, CPU se pak vrátí nazpět. Úspěšnost odhadu je pro výkon kritická a nové architektury proto predikci stále vylepšují, což platí i pro Zen 3. Používá dále prediktor typu TAGE (zavedený v Zenu 2), ale AMD zvětšilo L1 Branch Target Buffer na dvojnásobek (z 512 na 1024 položek), což by mělo vylepšit úspěšnost. L2 Branch Target Buffer byl mírně zmenšen z 7000 na 6500 položek, asi proto, aby byl energeticky efektivnější (nebo šlo o cenu za zvětšení L1 BTB o podobný počet). Struktura Indirect Target Array se zvětšila z 1024 na 1536 položek.
Toto by mělo zvýšit účinnost (která se asi může zlepšit i jiným laděním, které AMD přímo nepopisuje). Predikce ale má také větší výkon – AMD uvádí, že je možné předvídat více větví za cyklus než dříve (snad dvě větvení místo jednoho?). Současně prý také mají většinou být eliminovány „bubliny“, kdy pár cyklů trvá, než se po predikci procesor přepne na vykonávání z nové adresy. V Zenu 3 prý u většiny predikcí vzniká „nulová bublina“. Údajně by snad také mohla být zredukována cena za špatný odhad (kdy se CPU vrací a musí začít znovu), ale AMD neuvádí, kolik cyklů teď tzv. misprediction penalty čítá.
Prefetch
Kromě predikce větvení AMD také vylepšilo prefetch, tedy spekulativní předběžné načítání dat z paměti předtím, než je CPU hypoteticky bude potřebovat. Také zde bývají architektury kontinuálně vylepšovány. V Zenu 3 by měl být prefetch účinnější v předvídání toho, jaká data bude program požadovat z paměti. Například má být vylepšený prefetch v situacích, kdy vzorec přístupů překračuje hranice paměťových stránek.
Podle AMD tyto věci také mají značný podíl na zlepšení IPC, kterého Zen 3 dosáhl. Vylepšený pretech údajně zvýšil výkon o 2,7 %, k tomu vylepšení predikce větvení o dalších 1,3 %. Ostatní části frontendu mají dávat dalších +4,6 %, ale už není popsáno, z čeho to přesně pramení. Pravděpodobně může být zahrnuté ještě vylepšené optimalizování out-of-order vykonávání instrukcí (zvětšený reorder buffer, o kterém bude řeč později).
⠀
- Contents
- AMD Zen 3: nová architektura, Op cache a frontend
- Překopaný výpočetní backend ALU a load/store
- Floating point a SIMD část
- Cache a velká změna s 8jádrovým CCX
- Jak velké je výšení IPC a koncepce Zenu 3




Moc pekny clanek. Diky JO 🙂
Zdravím, taková otázka na autora. Můžem čekat více článků od tebe na tomto webu, vzhledem k situaci s cnews. Nebo jsou nějaké jiné plány?
klikni na autora auvidíš, koľko tu má článkov a budeš prekvapkaný, aký dlhý čas už!
Bez ohľadu na to, ako to dopadne so Cnews (verím, že pozitívne a čoskoro bude fungovať tak ako predtým), tak by Jano mal vo väčšom objeme vydávať články aj u nás. Celkovo sa na HWC čoskoro dočkáte veľkých zmien, na ktoré sa už pripravujeme dlhší čas a štart je blízko. 🙂
těšíme se… 🙂
číta sa to dobre, paráda, díkes 🙂
ešte tak prilákať Vítka a Rybku!