




Minulý měsíc AMD vydalo procesory Ryzeny 5000. Jejich architektura Zen 3 přinesla nakonec možná víc, než se čekalo, výkon na 1 MHz někde převyšuje i IPC nejnovějšího jádra Intelu Willow Cove (Tiger Lake). Zen 3 je podle AMD jeho největší překopání architektury od vůbec prvního Zenu, pročež se podíváme, jaké změny v něm inženýři provedli, aby dokázali porazit Intel i v jednovláknovém a herním výkonu.
Výpočetní jednotky: částečné rozšíření v ALU i FPU části
Řekli jsme, že počet ALU zůstal stejný, ale svým způsobem jádro přece jen bylo rozšířeno. Zatímco Zen 2 měl v celočíselné výpočetní části čtyři ALU a tři AGU, Zen 1 se lišil jen dvěma AGU (Adress Generation Unit, plní Load/Store operace), Zen 3 má trošku jinou skladbu – schopnosti jednotek byly trošku přerozděleny a zvýšil se počet portů neboli šířka „issue“. Ta je teď deset portů.
Místo sedmi (4×ALU, 3×AGU) má Zen 3 čtyři ALU a tři AGU , ale k tomu ještě novou vyhrazenou jednotku pro zpracování větvení (na schématu „BR“). Ta je již druhá, neboť vedle ní tuto funkcionalitu provádí ještě jedna ALU. Devátý a desátý port jsou také nově přidané separátní porty zpracovávající ukládání dat do paměti (přesněji L1 cache) – na schématu jsou vyznačené jak „ST“.
Celkově tedy jádro může zpracovat čtyři aritmeticko-logické operace za cyklus jako Zen 2. Ovšem v případě, že je třeba provést větvení, tato operace jde do nové jednotky a neubere tedy z kapacity ALU, v takové situaci tedy zlepšení IPC nastane. To je obecně smysl této reorganizace, kdy má jádro sice podobné počty jednotek jako dříve, ale jsou rozdělené mezi větší počet portů – tímto je možné více funkcionality obsloužit současně, zatímco při menším počtu portů operace častěji jedna blokují druhou, protože by potřebovaly jít na stejný port.
U Zenu 3 některé také ALU instrukce mohou být vykonávány ve větším počtu za takt (LAHF, LZCNT, POPCNT, ale i další), nebo s vyšší latencí. Dost se například latence snížila u celočíselného dělení (kde se i zvýšil počet operací dělení proveditelných na jeden cyklus, respektive za určitý počet cyklů).
Výrazné posílení Load/Store
Kapacita Load/Store operací je tři čtení za cyklus a dva zápisy za cyklus, zatímco Zen 2 uměl dvě čtení a jeden zápis za jeden cyklus. Zde je to tedy znatelné navýšení kapacity. Mimochodem, současná jádra Intelu (procesory Ice Lake/Tiger Lake) by měly umět jen dvě čtení a dva zápisy za cyklus. Ovšem u Zenu 3 je tato kapacita trošku omezená – funguje jen u šířek dat do 128 bitů. Pokud je šířka dat 256 bitů, pak Zen 3 zvládne jen dvě čtení a jeden zápis za cyklus. Zen 3 jinak také prohloubil frontu zápisů (store queue), z 48 na 64 položek. Fronta čtení je naopak nezměněná (44 položek).
Toto posílení Load/Store části jádra je jinak jeden z větších faktorů ve zvýšeném IPC Zenu 3. Zlepšuje prý výkon na 1 MHz o 4,6 % v měření AMD. Více, než ostatní změny ve výpočetních jednotkách.
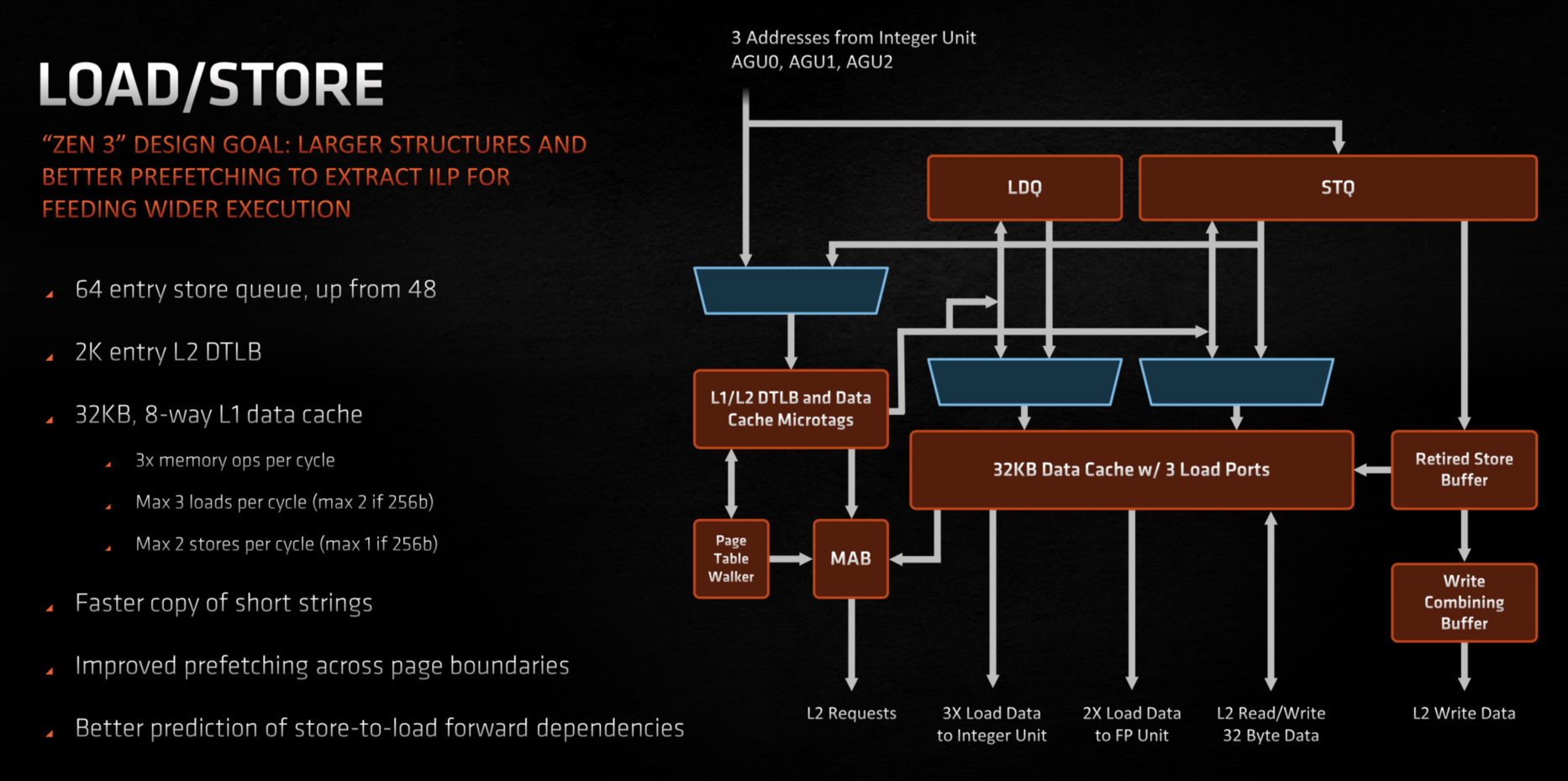
6× Page Walker
Jednotky load/store jsou prý díky přeorganizování jádra flexibilnějši použitelné a měla by být vylepšena schopnost procesoru identifikovat závislosti mezi load/store operacemi (store-to-load forwarding).
Kromě toho byly také výrazně posílené tzv. page walkery u translation lookaside bufferu (TLB), Zen 3 jich má šest místo dvou u Zenu a Zenu 2. Tyto jednotky vyhledávají fyzickou adresu určité požadované logické adresy v paměti, pokud se ji nepodaří najít v TLB (TLB miss). Jejich posílení by tedy mělo pomoci při operacích intenzivně pracující s operační pamětí, kdy se používá větší rozsah paměti a přístupů je paralelně víc najednou.
Velká reorganizace schedulerů
Kromě reorganizace portů podniklo AMD druhou velkou změnu v celočíselné části – překopány byly totiž i schedulery pro jednotlivé jednotky. Zen 1 a 2 měly pět schedulerů, separátní pro každý port ALU a jeden další scheduler společný pro všechny AGU. Jednotlivé schedulery se plnily z předchozí fáze zpracování, tzv. Integer Rename (kde se přemapovávají architektonické registry na větší počet fyzických registrů pro potřeby out-of-order vykonávání instrukcí).
Zen 3 toto mění. Místo pěti schedulerů má jádro nyní schedulery čtyři, kdy na každém je jedna ALU a jedna AGU (ALU jsou jenom tři, na čtvrtém scheduleru je navěšená čtvrtá ALU a k ní ona samostatná jednotka pro větvení). Separátní store data porty jsou zřejmě přidané na druhém a čtvrtém scheduleru. Tyto schedulery mají každý 24 položek. Je zajímavé, že tři schedulery vždy pro pár ALU+AGU už AMD používalo kdysi, v architekturách K7, K8 a K10, takže jde o jistý koncepční návrat k historii.

Jde o poměrně zajímavé uspořádání. Intel například používá stále jednotný scheduler pro celé jádro, na kterém jsou připojené všechny porty. V Zenu 1 a 2, jak již bylo řečeno, byly schedulery zcela samostatné pro jednotlivé ALU (měly hloubku 16) a scheduler pro AGU byl společný s hloubkou 28 položek. Jejich sdružení vždy pro pár ALU a AGU by mělo umožnit jejich lepší využití. Součet hloubky těchto front je 96, což je jen malé zvýšení z celkem 92 (4×16 + 28) v Zenu 2.
Onen společný scheduler u Intelu je větší – v Ice Lake/Tiger Lake má hloubku 160, u Skylake 97. Celková unifikace u Intelu by mohla být ještě další plus. Ale je možné, že pak zase Intel naráží na komplexnost implementace, takže to má i nevýhody.
Tato změna v uspořádání portů a schedulerů ve výpočetní části je každopádně asi nejvýraznějším znakem toho, že je Zen 3 opravdu nová architektura.
Hlubší out of order fronty
AMD také zvětšilo počet fyzických registrů, byť jen mírně, na 192 proti 180 registrům u Zenu 2. Tyto fyzické registry slouží pro přemapování architektonických registrů, s nimiž pracuje instrukční sada a je jich mnohem méně. Pro srovnání, 180 fyzických registrů má i Skylake, ovšem Ice Lake nejspíš počet také zvýšilo.
Architektury Intel Ice Lake/Tiger Lake ovšem hlavně výrazně zvýšily hloubkou hlavní out-of-order fronty sloužící pro přehazování a optimalizování pořadí instrukcí, tzv. reorder buffer (ROB) rovnou na 352 položek (Skylake mělo 224). Čekalo se, zda AMD udělá podobné velké navýšení, které u Intelu nejspíš hodně pomohlo ke zvýšení IPC, ale kupodivu se tak nestalo.
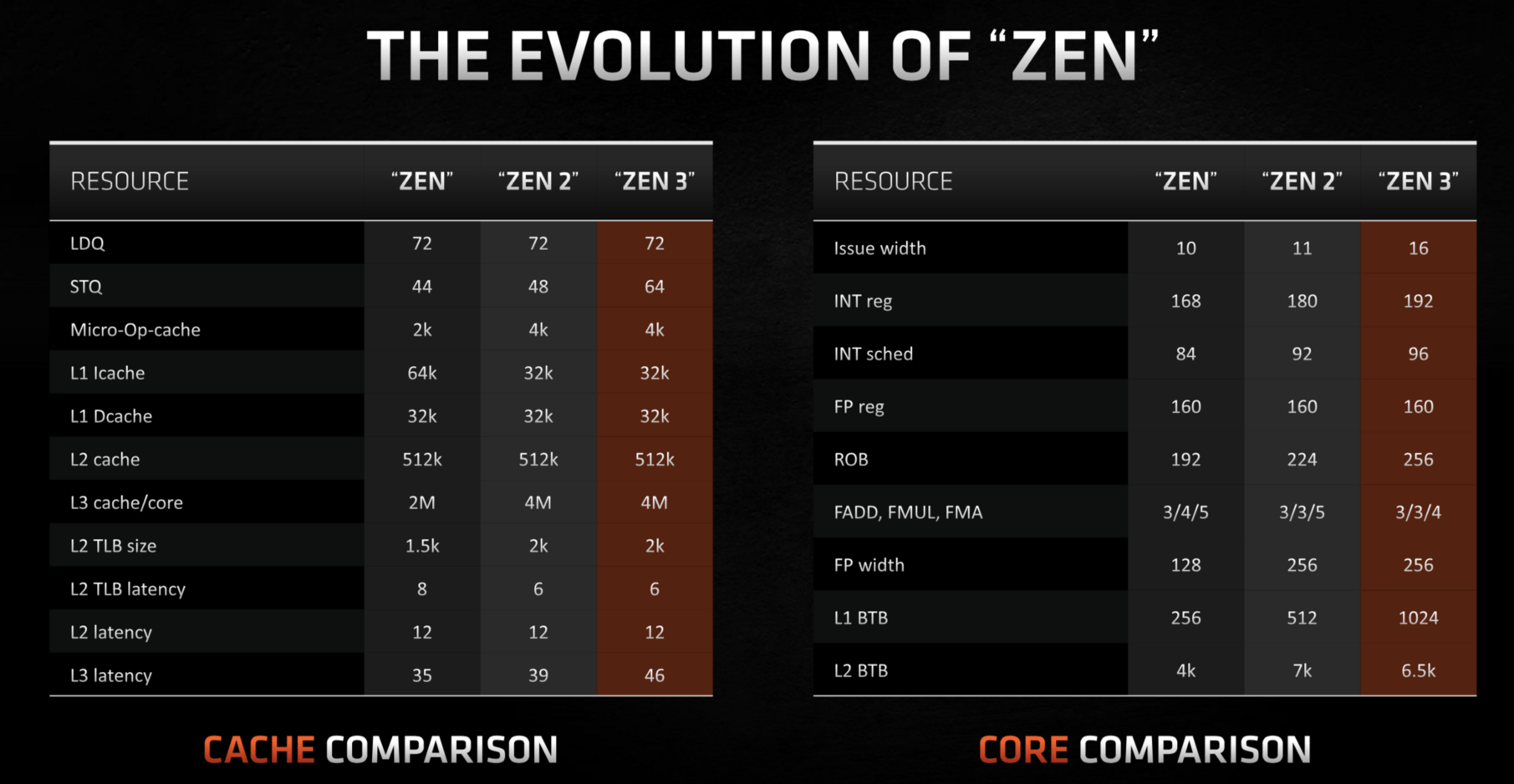
Zen 2 měl reorder buffer o 224 položkách jako Skylake a Zen 3 ho zvětšil jen mírně, na 256 položek. AMD šlo tedy cestou menších krůčků. Mimochodem, jádro Firestorm od Apple (v čipech M1 a A14) má podle měření reorder buffer hluboký možná až 600 položek – firma přesná čísla neprozrazuje, ale zdá se, že hloubku out of order front má stejně jako šířku jádra (počet ALU je 6) výrazně vyšší než jádra Intelu a AMD. Ovšem zase za cenu nižších taktů.
Obecně u hloubek front a bufferů, o nichž se zde bavíme, platí to, že čím hlubší jsou, tedy čím se do nich vejde víc položek, tím účinnější by měly být. Proč? Hlubší/delší fronta dovoluje lépe zpotimalizovat pořadí instrukcí. Out-of-order vykonávání operací je tím účinnější, čím větší je „okno“, které procesor při tomto optimalizování vidí. Pokud najednou může pracovat s 350 instrukcemi, má lepší příležitost přeházet je pro optimální výkon (tj. dosáhnout maximálního využití prostředků jádra a docílit tím co nejrychlejšího zpracování), než když jich najednou vidí jen 250.
Není to samozřejmě jediný faktor, ale procesor s hlubšími buffery má potenciál pro vyšší IPC (výkon na 1 MHz). Podobně jako přinášejí potenciál k vyššímu IPC větší cache oproti menším a širší jádra (tedy ta s vyšším počtem jednotek) oproti těm užším. Hloubky front jako je Reorder Buffer lze tedy použít k určitému porovnávání jader, ale i když nežříká všechno (podobně jako IPC není vše a je nutné započítávat i frekvenci) a zde zrovna vidíme, že procesory s tak výrazným rozdílem v hloubce Reorder Bufferu jako Tiger Lake a Zen 3 nakonec mohou mít podobné IPC.
⠀






Moc pekny clanek. Diky JO 🙂
Zdravím, taková otázka na autora. Můžem čekat více článků od tebe na tomto webu, vzhledem k situaci s cnews. Nebo jsou nějaké jiné plány?
klikni na autora auvidíš, koľko tu má článkov a budeš prekvapkaný, aký dlhý čas už!
Bez ohľadu na to, ako to dopadne so Cnews (verím, že pozitívne a čoskoro bude fungovať tak ako predtým), tak by Jano mal vo väčšom objeme vydávať články aj u nás. Celkovo sa na HWC čoskoro dočkáte veľkých zmien, na ktoré sa už pripravujeme dlhší čas a štart je blízko. 🙂
těšíme se… 🙂
číta sa to dobre, paráda, díkes 🙂
ešte tak prilákať Vítka a Rybku!