





Gracemont: „malá“(?) architektura silná už jako Skylake
Intel teď odhalil architekturu svých nejnovějších procesorů Alder Lake. Tentokrát jsou to ale architektury dvě. Alder Lake je hybridní a vedle „velkých“ jader pro jednovláknový výkon má další „malá“ jádra Gracemont. Ta ale nejsou jen do počtu či pro úsporu energie v nečinnosti jako u ARMů v mobilech, naopak se významně podílí na celkovém výkonu. Jejich architektura je vlastně sama celkem velká a teď se na ní detailně podíváme.
Gracemont je jádro, která podle Intelu bylo navrženo tak, aby mělo při co možná nejmenší ploše co možná nejvyšší výkon a díky tomu se s ním dalo dosáhnout dobrého škálování monohovláknového výkonu. Jádro by mělo mít výkon až někde okolo architektury Skylake – tedy aspoň pokud by jejich frekvence byly stejné – ale nižší spotřebu.
Cíl bylo, aby Gracemont měl vyšší IPC než Skylake, ale jádro je navržené na běh na nízkých napětích, takže spotřeba má prý být „zlomková“. Dokonce by prý mělo jít o x86 jádro s nejvyšší energetickou účinností (tedy nejlepším poměrem výkon/watt) na světě.
Poměrně významný rozdíl ale je, že jde jen o jádro zpracovávající jedno vlákno. Chybí technologie HT. Zda ji Intel v tomto druhu jádra nechce mít (kvůli komplexitě, spotřebě, tranzistorech navíc), nebo se jen ještě nedostal k tomu, aby ji do E-Core přidal a v budoucnu se zde také objeví, to nevíme. HT benefituje z širokého výkonného jádra, což Gracemont až překvapivě silně je.

Frontend s 2×3 dekodéry
Na Gracemontu je jasně vidět, že vychází z předchozí „Atomové“ architektury Tremont, ale jádro je stejně jako Golden Cove proti předchůdcům značně rozšířeno. Jádro po Tremontu přejímá jeho nejvýraznější rys: dekodéry, které jsou rozdělené do dvou klastrů po třech – počty zůstaly stejné. Tyto dva klastry nejsou rovnocenné šesti dekodérům v jádru Golden Cove, při dekódování proudu instrukcí se nemohou spřáhnout dohromady a dekódovat šest po sobě následujících instrukcí. Mohou jen paralelně dekódovat dva proudy instrukcí, každý po třech instrukcích za cyklus. Toto řešení je proti šesti dekodérům energeticky úspornější.

K současnému využití obou skupin dekodérů dochází tehdy, když procesor kvůli větvení ví, že bude skákat na určitou adresu v kódu, kterou může druhý klastr dekodérů použít jako startovní bod a začít od tohoto místa paralelně dopředu dekódovat. Větvení mohou být v kódu hodně častá (při vydání Tremontu se mluvilo, že mohou nastávat v průměru třeba i každých šest instrukcí), což by dovolovalo druhý klastr dekodérů využít překvapivě často.
Zatímco kapacita dekodérů je stejná jako u Tremontu, Intel zvětšil na dvojnásobek L1 instrukční cache, která má místo 32 KB teď 64 KB (paradoxně 2× víc, než v Golden Cove). Stejně tak byla zvětšena Branch Target Cache prediktoru větvení (na 5000 položek, velikost v Tremontu nevíme), což zlepší jeho úspěšnost. Prediktor si má pamatovat poměrně dlouhou historii, což by opět mělo pomáhat úspěšnosti.

Predecode informace v L1 instrukční cache
Jádro používá optimalizaci nazvanou On-Demand Instruction Length Decode. Ta by měla spočívat v použití pre-dekódování při načítání dat do L1 instrukční cache, které zjistí délky instrukcí a udržuje tuto informaci v L1 jako metadata (takže procesor už bude vědět, kde jednotlivé instrukce začínají). Tato informace se pak používá při opětovném provádění stejného kódu z L1 cache, kdy se díky tomu část práce dekodérů ušetří (a tím se také uspoří energie).
Gracemont nepoužívá μOP cache pro cachování již dekódovaných instrukcí a jejich opětovné použití, což větší x86 jádra (Intel od Sandy Bridge, AMD od Zenu, ARM od Cortexu-A77) implementují pro snížení spotřeby. Predecode a cachování délky instrukcí je zřejmě jakási zjednodušená náhrada, která je asi méně náročná na implementaci a množství tranzistorů, i když asi také méně pokročilá.
Velké posílení hlavně Out-of-order enginu a výpočetních jednotek
Zatímco Golden Cove provedlo největší rozšíření jádra ve Frontendu a menší v Backendu procesoru (samotných výpočetních jednotkách), Gracemont je tak trošku opačný případ. Frontend proti Tremontu není tak zvětšený, ale Backend výpočetních jednotek naopak velmi. Společné s Golden Cove ale je, že byla posílená prostřední část, kde dochází k optimalizaci a přehazování instrukcí stylem out-of-order.
Fáze Allocation umožňuje v Gracemontu zpracovat až pět instrukcí (μOPů) přicházejících z fáze dekódování a fronty μOP Queue za cyklus. Je to zlepšení o čtvrtinu proti Tremontu (ten je v této fázi pipeline jen 4-wide) a není to moc daleko od jádra Golden Cove, které má fázi Allocation zpracovávající až šest instrukcí za cyklus (6-wide). V této fázi se μOPům přiřazují jejich pracovní registry a dále se provádí přejmenování registrů kvůli konfliktům, které umožňuje instrukce používající kolidující architektonické registry vykonat současně. Zde také procesor dokáže eliminovat některé operace, které nepotřebují jít dál do výpočetních jednotek (MOV Elimination, Zeroing Idiomy).
Out-Of-Order okno jako má Zen 3
Po této fázi v procesoru následuje Re-Order Buffer (ROB), tedy fronta instrukcí, v níž procesor jejich pořadí přehazuje tak, aby se jich co nejvíce vykonalo paralelně a tím se využily pokud možno všechny dostupné jednotky. Out-of-order procesor může instrukce, které na sobě nezávisejí, vykonat paralelně a pokud nejbližší instrukce zatím nemají splněné závislosti nebo pro ně chybí data, může místo nich zatím počítat dopředu instrukce, které budou následovat v kódu dále. Toto kód „zkompaktní“ a k jeho vykonání je pak třeba méně cyklů. Ale pro co nejlepší účinnost tohoto přeorganizování je třeba, aby procesor „viděl“ co největší kus kódu, a tento kus představuje právě délka fronty Re-Order Buffer.
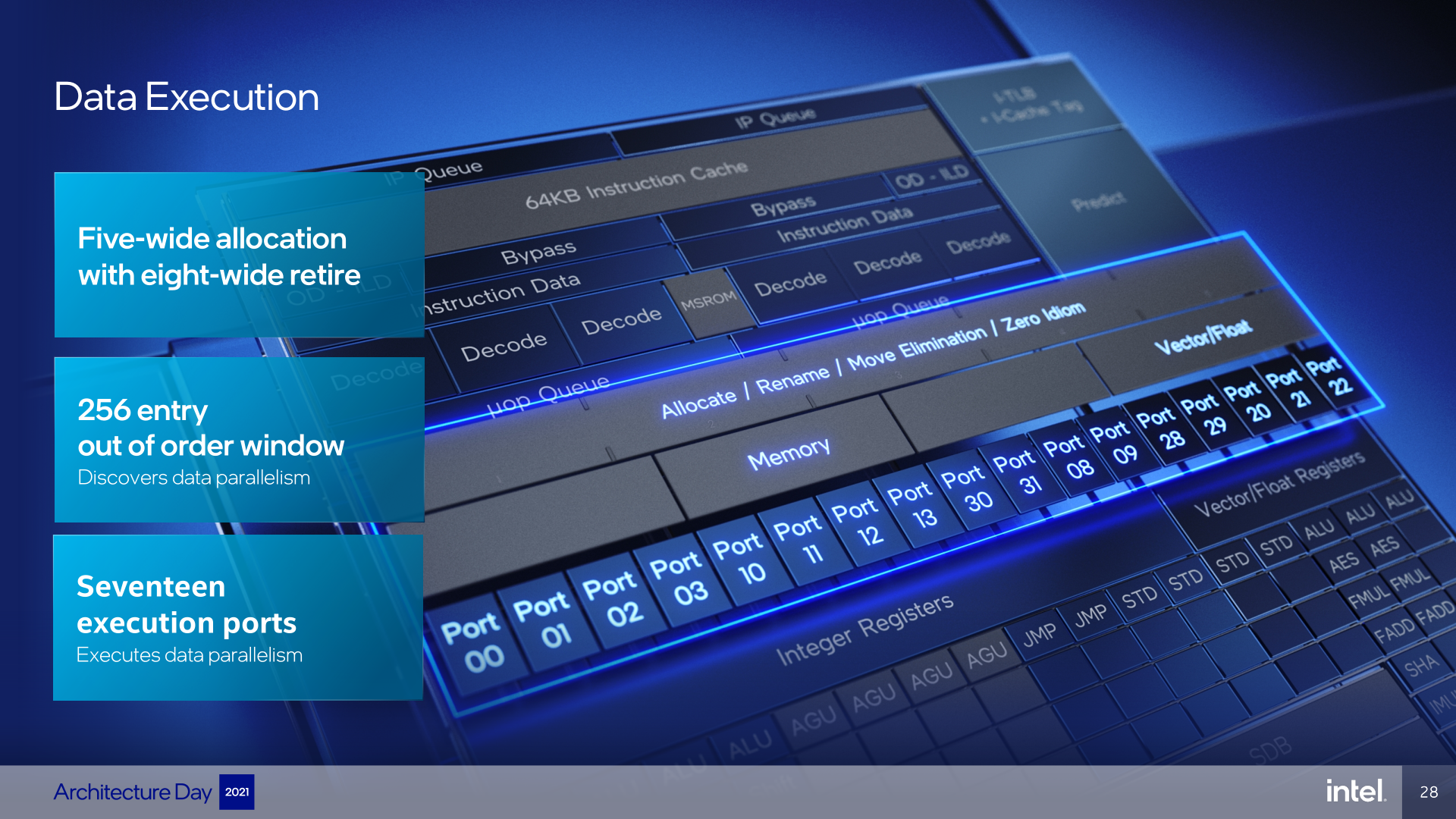
Intel ho v Gracemontu použil docela velký – má totiž 256 položek. Je to sice jen polovina ROB, který má Golden Cove (512 položek), ale víc, než má architektura Skylake (224 položek), a co je pozoruhodné, stejná hloubka ROB, jakou má AMD u Zenu 3 (také 256). Je sice pravda, že Zen 3 je asi spíš výjimka, kde je ROB netypicky malý na to, jak je jádro výkonné, ale to, že má Gracemont 256 položek, dobře ukazuje, jak se vymyká z kategorie „malého jádra“.
Článek pokračuje další kapitolou.
- Contents
- Velká a „malá“ jádra: proč vůbec?
- Gracemont: „malá“(?) architektura silná už jako Skylake
- Výpočetní jednotky: 17 portů, potenciál pro vysoké IPC
- Paměťový subsystém: Dvakrát víc AGU a Load/Store
- Rychlost: „Malé“ jádro má až dvě třetiny výkonu velkého





