





Longtime rivals AMD and Intel have established a joint consortium seeking to make their x86 processors and their future extensions more compatible instead of using the differences and exclusive features as (anti)competitive advantages. In autumn they settled on several extensions to be made standard: AVX10/AVX-512, APX, ChkTag, FRED, and also the ACE matrix extension for AI compute, about which very little had been known until now.
The x86 Ecosystem Advisory Group consortium has now published documentation describing ACE (AI Compute Extensions) and showing how this instruction set extension—or perhaps more accurately, accelerator—will function. Originally, it was expected that ACE would simply be a new name for AMX technology. Intel has already had AMX in server processors for some time, so it would have made sense to take it and standardise it across all x86 CPUs, much like AVX10 is essentially an adoption of the original AVX-512 extension.
That does not appear to be the case, however, and ACE seems to be a new extension that will not be compatible with AMX. It is possible the consortium chose an alternative extension AMD is preparing instead of Intel’s AMX (ACE could apparently be implemented by the Zen 7 architecture, which according to the official roadmap is set to introduce expanded AI acceleration). The ACE documentation includes wording suggesting AMD is the primary author—and most of the paper’s authors are AMD employees. Until now, most new additions to the x86 instruction set came from Intel, as the larger competitor holding dominant control over it, but AMD now apparently has enough influence to (at least occasionally) impose its own direction, too.
However, ACE will to some extent be grafted onto how the AMX extension is exposed to programmers within the x86 instruction set, and Intel also contributed to ACE at least in a later phase following the founding of the x86 Ecosystem Advisory Group consortium—so this new extension is not without Intel’s involvement. This linkage to AMX (though in an incompatible manner) should simplify adding support to operating systems and developing software for the new extension.
AMD, in partnership with Intel and the x86 EAG (Ecosystem Advisory Group), is readying ACE as the standard matrix acceleration architecture for x86, further enhancing the already vibrant x86 ecosystem.
Integration with AVX10 (and AVX-512)
ACE instructions are intended to accelerate artificial intelligence operations, particularly matrix multiplication and outer product operations. A specialty of this extension is that it is designed to build directly on AVX-512, or more specifically AVX10, which are 512-bit SIMD instructions. ACE introduces new matrix (tile) registers that it operates on, but the goal is for ACE operations to directly cooperate with AVX-512/AVX10 operations and build upon them in code.

ACE introduces eight architectural “tile registers” into the x86 instruction set, each 512 bits wide with 16 rows, allowing storage of a 16 × 16 matrix of values using a 32-bit data type (for accumulation). In addition, a single Block Scale Register is introduced with a width of 1024 bits. These registers will become a new addition to processor state that must be saved during context switching.
The design seem to suggest that these new registers will be implemented within the processor core using the same physical register file used for the 512-bit ZMM registers belonging to AVX-512/AVX10—allowing efficient reuse of infrastructure and transistors already invested in AVX-512 by processor cores.

ACE operations are expected to use ZMM (AVX-512/AVX10) registers as inputs and tile registers as the accumulator and output. For this purpose, a 512-bit ZMM register stores four rows, each containing 16 values using 8-bit data types. AVX10/AVX-512 operations will also be used for preparing inputs, and it will also be possible to rapidly convert results from matrix registers into SIMD ZMM registers.
In line with its AI-focused design, ACE supports using various reduced-precision numerical formats—8-bit integer INT8, 8-bit floating-point formats OCP FPM8, OCP MXFP8, and MXINT8, as well as 16-bit Bfloat16. Smaller data types could likely be added in the future in theory, such as FP6 or especially FP4. Currently, ACE includes instructions for conversion to and from these formats, but does not yet include instructions for direct compute operations with them.
First Processor Support in 2028?
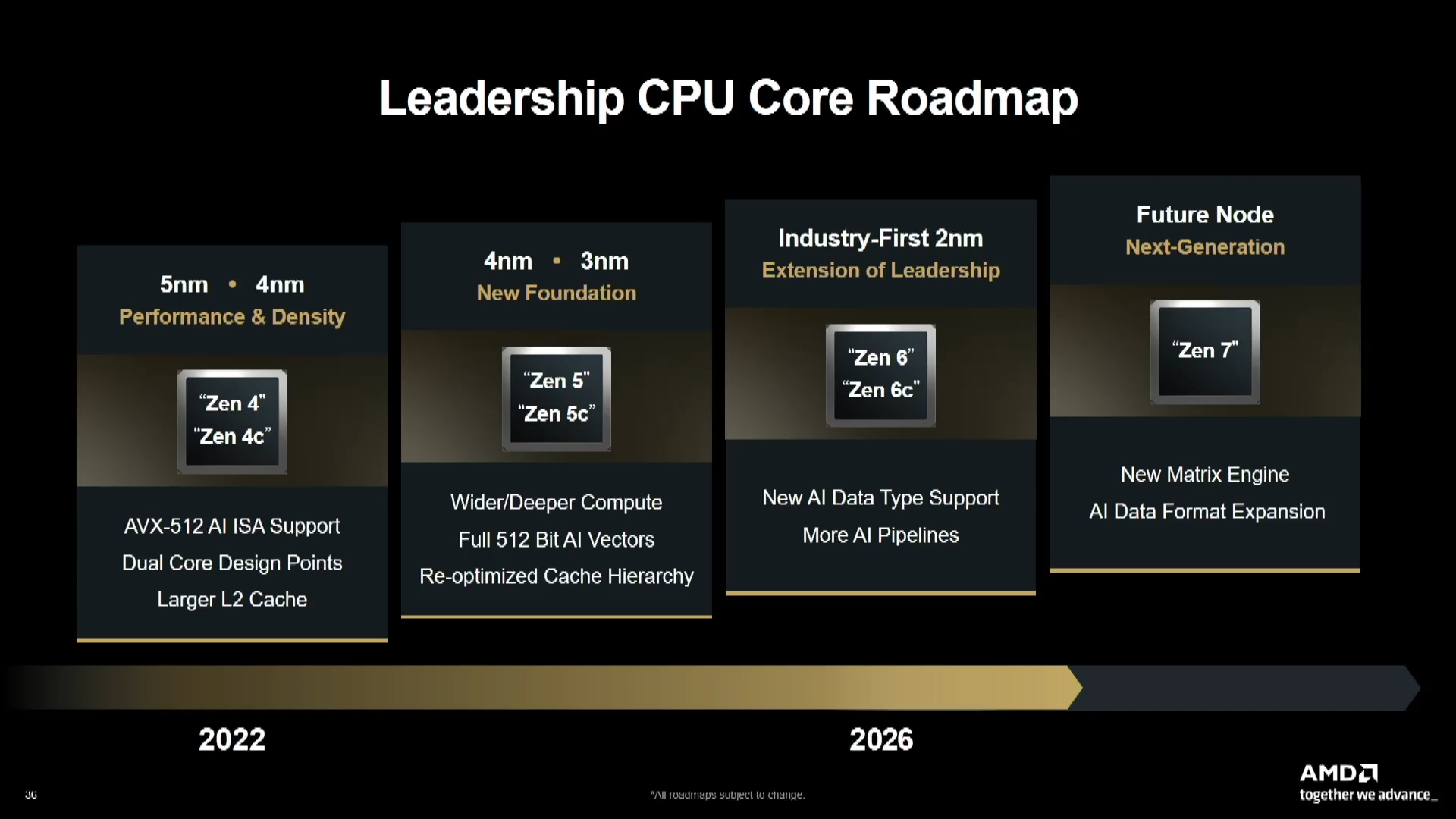
As previously mentioned, AMD announced that Zen 7 processors will include some form of AI acceleration extensions. Originally, these were assumed to correspond to Intel AMX-like extensions, but it now appears AMD is instead preparing support for its own technology, under the ACE name. Zen 7 is apparently scheduled for release in 2028 and could become the first—or among the first—architectures to provide ACE support. It may also be included across all core variants, including those in Ryzen mobile SoCs. The documentation states ACE support is intended to span x86 processors broadly—whereas AMX was available only in Intel Xeon server CPUs, ACE is intended for processors ranging from servers to notebooks. The timeline for Intel processor support remains unclear.
It is worth recalling that AMD and Intel also agreed to standardise AVX10 instructions in their 512-bit form across all CPUs. If ACE support can be implemented in an AVX10-equipped core through shared use of the physical register file without requiring too many additional transistors, this extension could potentially become part of all x86 cores rather than a separate accelerator outside the core.
For example, the AMX accelerator in Apple processors (and now the SME unit that is taking over its role) is a case of a separate accelerator existing outside the CPU core and present in smaller numbers than CPU cores. Note that Apple’s AMX is unrelated to Intel’s AMX, though it serves a similar purpose. These units are typically present in only one instance per core cluster and are shared among the cluster’s cores.
Whether ACE will become a direct part of CPU cores themselves, however, remains to be seen—it is not impossible that in the end the unit may also be shared across multiple cores to conserve die area.
Source: x86 Ecosystem Advisory Group
English translation and edit by Jozef Dudáš
⠀

